
Статьи
Платежи в приложении через Google Pay: почему это важно
mCommerce становится еще привлекательней.
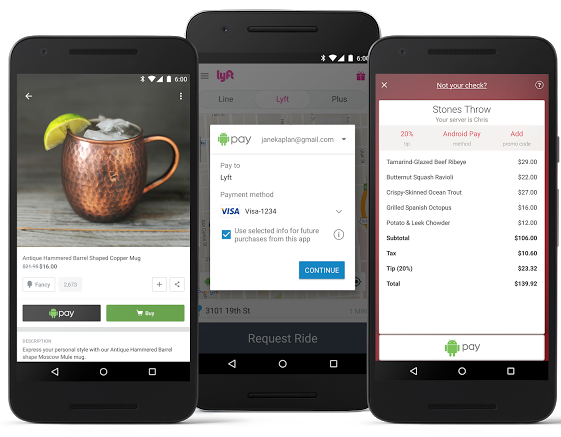
Владимир Макеев (Surf) поделился с нами своими мыслями по поводу запуска платежной системы Android Pay в приложениях.
На этой неделе произошло важное для m-commerce событие. Google позволил оплачивать физические товары картой, привязанной к Pay.
Почему этого не было раньше?
Google и Apple продают цифровой контент с комиссией 30%. Продажа физических товаров через встроенные покупки ими запрещена. Ну и очевидно, что разработчикам торговать с такой комиссией не выгодно. Поэтому сейчас оплата еды, одежды и билетов реализуется через банки и платежные шлюзы.
Почему сейчас все плохо?
Для оплаты покупки нужно вводить данные банковской карты в специальную форму и подтверждать операцию через код из SMS. Данные карты, как правило не сохраняются, и для повторных покупок ввод нужно выполнять заново. Разумеется, все это снижает продажи. Со стороны разработчика реализация такой оплаты – процесс громоздкий и занимает до недели времени.

Так что сделал Google?
Покупки можно будет оплачивать «в один клик» картой, привязанной к Google Pay. Данные банковской карты при этом хранит Google. Больше не нужно договариваться с банками и платежными агрегаторами или получать PCI-DSS, а интеграция перестает быть громоздкой и будет занимать один день. Этим Google отнимает у банков комиссию в 1-2% со всех продаж в приложениях.
Когда это можно начать использовать?
Сейчас платежи через Google Pay доступны только в США. Google обещает в 2016 запустить сервис в Австралии и других странах. Надеюсь, к 2017 это дойдет до России.
mCommerce становится еще привлекательней.


-

 Разработка1 месяц назад
Разработка1 месяц назадЧистка Android-проекта для уменьшения размера APK, ускорения сборки и улучшения опыта разработки
-
Разработка1 месяц назад
Поваренная книга SwiftUI: лучшие практики управления состояниями в SwiftUI
-
Разработка1 месяц назад
Прекратите спорить в Code Review — начните внедрять с правилами линтера
-
Разработка1 месяц назад
Разработка, управляемая тестами (TDD), для исправления ошибок







