


Много лет главной целью системы рекомендаций Netflix было предоставлять пользователям правильные фильмы в правильное время. С тысячами фильмов и сотней миллионов пользователей жизненно важно советовать именно то, что нужно. Но работа рекомендательной системы на этом не заканчивается. Почему вам стоит посмотреть этот фильм? Что интересного мы можем сказать о новом и незнакомом для вас названии? Как убедить вас, что это стоит посмотреть?
Ответить на эти вопросы нужно, чтобы помочь пользователям найти отличный контент, особенно это относится к незнакомым названиям. Один из способов решения этой проблемы — рассмотреть изображения, которые мы используем вместе с названиями. Если это изображение представляет что-то привлекательное для вас, оно может стать точкой входа, которая подскажет вам, почему этот фильм или сериал может быть вам интересен. На нем может быть изображен знакомый актер, захватывающий момент, вроде погони на автомобиле, или драматическая сцена, передающая суть картины или сериала.
Если мы показываем это идеальное изображение на вашей домашней странице (как говорится, изображение стоит тысячи слов), тогда, возможно, вы посмотрите этот фильм. Этим Netflix также отличается от традиционных медиа: у нас не один продукт, а 100 миллионов разных продуктов — для каждого из наших пользователей, и каждый продукт включает в себя персональные рекомендации и персональные изображения.


Страница Netflix без изображений. Так наши алгоритмы видели её раньше.
Ранее мы обсудили наши попытки найти идеальное изображение для всех наших пользователей. При помощи множественных алгоритмов мы искали лучшее изображение, например, для «Очень странных дел», которое привлечет больше всего пользователей. Но не лучше ли будет найти лучшее изображение для каждого из наших пользователей, чтобы подчеркнуть релевантные для них аспекты названия?


Изображения для «Очень странных дел», которые получили более 5% переходов. Разные изображения показывают разные темы сериала.
Давайте рассмотрим случаи, в которых персонализация изображений будет иметь смысл. Взгляните на изображения с фильмами, которые ранее посмотрели пользователи. Слева — три обложки для фильмов, которые пользователь посмотрел ранее. Справа — обложка для конкретного фильма, которую мы посоветуем этому пользователю.
Давайте попробуем персонализировать изображение для фильма «Умница Уилл Хантинг». Мы можем сделать это на основе предпочтений пользователя в жанрах и темах. Если кто-то посмотрел множество мелодрам, то ему может быть интересна обложка с Мэттом Деймоном и Минни Драйвер; а пользователю, посмотревшему много комедий, может приглянуться обложка с известным комиком Робином Уильямсом.


В другом примере давайте рассмотрим, как предпочтения в актерах повлияют на персонализацию обложки «Криминального чтива». Если человек посмотрел много фильмов с Умой Турман, он позитивно ответит на обложку с Умой; а фанат Джона Траволты будет заинтересован в обложке с Джоном.

Конечно, не вся персонализация обложек настолько проста и очевидна. Поэтому мы полагаемся на данные, которые говорят нам, какие сигналы использовать. В целом персонализированная обложка помогает показать каждый фильм с лучшей стороны для конкретного пользователя.
Сложности
В Netflix мы адаптируем многие аспекты пользовательского опыта: ряды для домашней страницы, названия этих рядов, показанные галереи, сообщения и так далее. Каждый аспект имеет свои сложности, как и персонализация обложек. Одна из проблем заключается в том, что мы можем выбрать только одно изображение для фильма. Обычно настройки рекомендации позволяют нам показывать пользователю несколько вариантов, так мы постепенно узнаем о предпочтениях клиента. Это означает, что выбор изображения является проблемой курицы и яйца: если пользователь выбирает фильм, это может быть результатом только того изображения, которое мы решили представить пользователю.
Мы хотим понять, когда конкретная обложка повлияла на то, что пользователь посмотрел (или не посмотрел) фильм, и когда обложка не повлияла на решение пользователя. Таким образом, персонализация обложек становится одной из самых сложных проблем с рекомендациями, когда алгоритмы должны работать совместно друг с другом. Конечно, для этого нам нужно собрать большое количество данных, чтобы найти сигналы того, что одна обложка значительно лучше другой.
Кроме того, нужно понять влияние изменение обложки, которую мы показываем пользователю между сеансами. Влияет ли изменение обложки на узнаваемость названия, если, например, пользователь заинтересовался фильмом или сериалом, но не посмотрел его? Или изменение обложки уже заставляет пользователя рассмотреть этот фильм снова? Если мы найдем обложку лучше, мы, вероятно, будем использовать её, но постоянные изменения могут запутать людей. Изменение изображения также ведет к появлению проблемы атрибуции, когда становится непонятно, какая именно обложка привлекла пользователя.
Третья сложность заключается в понимании взаимодействия обложки с другими изображениями на той же странице или в том же сеансе. Может быть, портретная съемка главного героя работает, потому что выделяется среди других изображений. Но если каждый фильм представлен подобным изображением, то страница может быть не такой привлекательной. Недостаточно смотреть на отдельное изображение, мы должны думать о выборе набора изображений для страницы и для сеанса. Помимо других изображений, на эффективность могут влиять другие материалы (синопсис, трейлер и так далее). Таким образом, нам может понадобиться разнообразная подборка, которая будет выделять привлекательные для пользователя аспекты названия.
Чтобы достичь эффективной персонализации, нам нужна хорошая подборка изображений для каждого фильма и сериала. Нам нужны информативные и привлекательные материалы, чтобы избежать кликбейта. Набор изображений должен быть также достаточно разнообразным, чтобы покрыть широкую потенциальную аудиторию. Но все равно информативность и привлекательность обложки зависит от человека, который её увидит. Поэтому наши обложки должны не только показывать разные темы, но и иметь разную эстетику. Наши художники и дизайнеры стремятся создать изображения, которые будут различаться в разных измерениях. Они также принимают во внимание алгоритмы персонализации, которые выбирают изображения в ходе их творческого процесса.
Наконец, существуют технические сложности в масштабной персонализации обложек. Во-первых, наш пользовательский опыт во многом визуален и содержит множество изображений. Поэтому использование персональных подборок означает управление 20 миллионами запросов в секунду. Такая система должна быть надежной: медленная загрузка изображений значительно влияет на опыт. Наш алгоритм должен быстро отвечать при запуске фильма, что означает обучение персонализации в ситуации холодного старта. После запуска алгоритм должен продолжать адаптироваться, так как эффективность обложки может меняться со временем.
Подход «контекстуальные бандиты»
Большая часть рекомендательного движка Netflix основана на алгоритмах машинного обучения. Обычно мы собираем партию данных о том, как пользователи используют наш сервис, затем мы запускаем новый алгоритм на основе этой партии данных. Потом мы тестируем новый алгоритм на существующей системе при помощи A/B-теста, который при помощи тестирования на случайных пользователях помогает нам увидеть, лучше ли работает новый алгоритм. К сожалению, этот подход включает один минус: долгое время многие пользователи не используют лучший алгоритм. Это показано ниже:
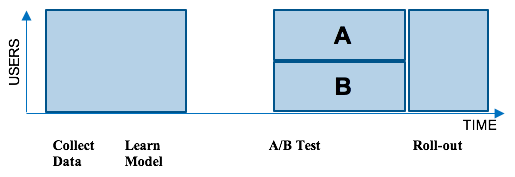

Чтобы устранить этот недостаток, мы перешли от группового машинного обучения к онлайновому машинному обучению. Для персонализации обложек мы используем особый фреймворк под названием «контекстуальные бандиты». Вместо того, чтобы собирать данные, ждать обучения модели и завершения A/B-теста, контекстуальные бандиты быстро вычисляют оптимальную подборку изображений для каждого пользователя и контекста.
Контекстуальные бандиты — это класс алгоритмов онлайн-обучения, которые непрерывно обучаются и применяют модель к любому пользовательскому контексту. В предыдущей работе по неперсонализированной выборке изображений мы использовали неконтекстуальных бандитов и искали лучшее изображение вне контекста. Сейчас контекстом является пользователь, так как мы ожидаем, что разные люди будут по-разному реагировать на изображения.
Данные для обучения контекстуальных бандитов собираются при помощи инъекций контролируемой случайности в предсказания обученной модели. Схемы рандомизации могут отличаться по сложности: от простых эпсилон-жадных алгоритмов до зацикленных схем, которые адаптируют степень рандомизации как функцию неопределенности модели. Мы называем этот процесс исследованием данных. Выбор стратегии диктуется количеством кандидатов на обложку и количеством людей, на которых будет развернута система. При этом нам нужно сохранять информацию о рандомизации для каждого выбора обложки. Это позволяет нам корректировать селекцию и оценивать модель офлайн без предрассудков.
Исследование при помощи контекстуальных бандитов имеет недостаток: наша селекция изображений в ходе сессии может не всегда использовать лучшую обложку. Какое влияние имеет рандомизация на пользовательский опыт? Обычно это влияние оказывается незначительным, так как распределяется по всем пользователям в нашей большой базе, и каждый из пользователей предоставляет данные по небольшой части каталога. Поэтому стоимость исследования оказывается незначительной, и это стоит всегда учитывать при выборе контекстуальных бандитов в качестве ключевого компонента.
При исследовании мы собираем обучающие данные для каждого фильма, пользователя или изображения, в которых записываем, произошло ли воспроизведение из-за селекции или нет. Более того, мы можем контролировать, что смена обложки не происходит слишком часто. Так мы яснее видим вовлечение пользователя на примере конкретного изображения. Мы также тщательно определяем качество вовлечения, избегая кликбейт-изображений.
Обучение модели
В процессе онлайн-обучения мы учим модель контекстуального бандита выбирать лучшую обложку на основе контекста. Обычно у нас есть несколько десятков изображений для каждого фильма или сериала. Чтобы обучить модель, мы можем распределить изображения независимо от пользователей. Даже так мы можем понять предпочтения пользователей, потому что для каждого изображения у нас есть те, кто перешел к фильму, и те, кто не перешел. Эти предпочтения можно использовать, чтобы предсказать вероятность для других фильмов и изображений. Это могут быть контролируемые модели обучения или контекстуальные бандиты с методами Томпсона, LinUCB или байесовскимими метода, которые сохраняют разумный баланс между лучшими предсказаниями и исследованием данных.
Потенциальные сигналы
В контекстуальных бандитах контекст обычно представлен вектором функций в модели. Существует много сигналов, которые мы можем для этого использовать. Мы можем рассмотреть многие атрибуты пользователя: просмотренные фильмы, их жанр, взаимодействия с конкретным названием, страна пользователя, их языковые предпочтения, используемое устройство, время суток и день недели. Так как наш алгоритм выбирает изображения вместе с движком персональных рекомендаций, мы можем использовать сигналы рекомендательных алгоритмов о том, что пользователь подумает о конкретном фильме или сериале.
Важно учесть, что среди кандидатов одни изображения будут лучше других сами по себе. Для всех изображений мы исследуем показатель take rate, то есть отношение количества качественных воспроизведений к количеству переходов. Ранее мы определяли лучшее изображение для всех пользователей. В новой модели эти показатели по-прежнему важны, и персонализация производит селекцию согласно ранжированию неперсонализированной модели.
Селекция изображений
Наша задача — найти лучшее изображений среди доступных. Как только модель обучена, мы используем её для ранжирования изображений в каждом контексте. Модель предсказывает вероятность воспроизведения для конкретного изображения и конкретного пользователя. Мы сортируем изображения по этой вероятности и выбираем лучшее, которое и показываем конкретному пользователю.
Оценка
Офлайн
Чтобы оценить алгоритмы перед развертыванием на реальных пользователях, мы используем офлайн-технику под названием replay. Этот метод позволяет нам ответить на гипотетические вопросы на основе данных об онлайн-исследовании (рисунок 1). Другими словами, мы можем сравнить, что бы произошло в уже состоявшихся сессиях, если бы мы использовали другие алгоритмы.

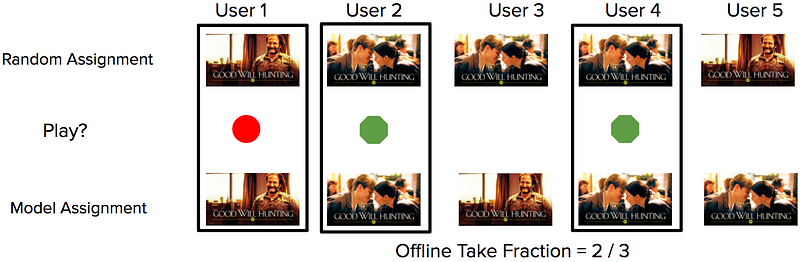
Рисунок 1: Простой пример вычисления replay на основе имеющихся данных. Для каждого пользователя было выбрано случайное изображение (верхний ряд). Система записала, был ли воспроизведен фильм (зеленый круг) или нет (красный круг). Далее соотносятся профили, в которых случайный выбор и выбор модели совпадают (черный прямоугольник), и на этом наборе производятся вычисления.
Replay позволяет нам видеть, как пользователи могли отреагировать на фильмы, если бы мы показали им изображения, выбранные новым алгоритмом. Рисунок 2 показывает, как контекстуальные бандиты помогают повысить показатель воспроизведения, take fraction, по сравнению со случайным выбором или неконтекстуальными бандитами.


Рисунок 2: средний take fraction (чем выше, тем лучше) для разных алгоритмов. Случайный выбор (зеленый) выбирает изображение случайно. Простой бандит (желтый) выбирает изображение с наибольшим take fraction. Контекстуальные бандиты (голубой и розовый) используют контекст для выбора разных изображений для разных пользователей.


Рисунок 3: Пример контекстуальной селекции на основе типа профиля. Контекстуальный бандит выбирает изображение комика Робина Уильямса для профилей, предпочитающих комедии, и изображение целующейся пары для профилей, предпочитающих романтические фильмы.
Онлайн
После офлайн-экспериментов мы запустили A/B-тест, чтобы сравнить лучшие контекстуальные бандиты и неперсонализированные бандиты. Как мы и ожидали, персонализация сработал и показала значительный рост наших ключевых метрик. Мы также увидели значительную корреляцию между тем, что мы измерили офлайн, и тем, что мы увидели онлайн. Результаты также показали несколько интересных инсайтов. Например, персонализация сработала лучше, если у пользователя ранее не было взаимодействия с фильмом или сериалом. Логично, потому что мы ожидали, что обложка будет более важна для человека, если название фильма ему незнакомо.
Заключение
При помощи этого подход мы сделали первые шаги в персонализированном выборе изображений в нашем сервисе. Это привело к значительным улучшениям, поэтому теперь этот алгоритм работает для всех. Этот проект — первый пример персонализации не только в том, что мы рекомендуем, но и как мы это делаем.
Этот подход можно расширять и улучшать. Можно разработать алгоритмы для холодного старта, которые будут персонализировать новые изображения и фильмы максимально быстро, например, при помощи методов компьютерного зрения. Другая возможность — расширение алгоритма на синопсис, метаданные и трейлеры. Существует и более обширная проблема — помочь художникам и дизайнерам понять, какие изображения нам стоит добавить в набор, чтобы сделать фильмы и сериалы ещё более привлекательными и персонализированными.