


Умение собирать и обрабатывать данные может пригодиться не только аналитикам. Дэниел Постон рассказал о своем опыте игры в покер, который поможет чуть лучше понять образ мышления, необходимый для того, чтобы использовать Data Science максимально эффективно.
15 апреля 2011 стал Черной пятницей для сообщества игроков в покер. В этот день правительство США запретило три главных сайта с онлайн-покером. В то время около 4 тысяч граждан США играли профессионально, поэтому началось массовое бегство. Стали популярными Канада и Коста-Рика. Я из Южной Калифорнии, поэтому знаком с мексиканской Нижней Калифорнией. Я решил открыть магазин к югу от границы в мексиканском городе Росарито.
Пока я готовился к переезду, меня часто спрашивали, что произойдет, если мой план не сработает. Игра в онлайн-покер требует понимания данных, вероятности и статистики. Тогда я знал только об одной профессии, применяющей тот же набор навыков. Я говорил: “Возможно, я начну работать аналитиком на Уолл-Стрит”.
В том же месяце вышел фильм “Человек, который изменил всё”. Действие основанного на книге Майкла Льюиса фильма происходит во время сезона 2002 года в команде “Окленд Атлетикс”. Используя анализ данных (Data Science), аналогичный используемый аналитиками с Уолл-Стрит, команда произвела революцию в бейсболе. С небольшим бюджетом они выиграли 20 игр подряд. В этот момент аналитика данных и стала мейнстримом. Год спустя в Harvard Business Review вышла статья Data Scientist: The Sexiest Job of the 21st Century. Glassdoor.com назвал работу Data Scientist главной профессией 2016 и 2017.
Что общего у Data Science и покера
Я начал карьеру в Data Science в 2016. Я заметил, что многое из того, что я узнал во время занятия покером, подходит и для сегментации пользователей. Откуда игрок в покер (географическая сегментация), как игрок думает (психографическая сегментация) и как он играет (поведенческая сегментация) — всё это очень важные факторы, определяющие стратегию против этого игрока. Я узнал, что все эти факторы можно свести к простой статистике. Я мог сказать, насколько игрок хорош, всего по двум числам. Чтобы протестировать эту теорию, я создал k-means модель, чтобы сегментировать оппонентов в покере так же, как компания сегментирует своих клиентов.
Данные для этого проекта были собраны в течение моей карьеры в покере. Я использовал программу Hold’em Manager, которая загружает историю каждой игры в реальном времени в базу данных PostgreSQL, чтобы отслеживать тенденции ваших оппонентов. История раздачи генерировалась после игры и объясняла всё, что каждый игрок делал во время игры. Эти тенденции показывались следующим образом:

Как я использовал Data Science, чтобы перехитрить своих оппонентов
В техасском холдеме каждый игрок получает две карты в начале игры, что означает, что у вас может получиться 1326 стартовых комбинаций. Статистика тенденций для оппонента — мощный инструмент, потому что при помощи него просто предугадать карты оппонента. Например, некоторые игроки редко повышают префлоп-ставку, если их процент повышения префлопа PFR низок. Если у оппонента PFR равен 2%, то у них может быть только 26 из 1326 комбинаций. А если они повышают ставку, то у них вероятны 28 из 1326 комбинаций.
Два числа, по которым я определяю, насколько хорош игрок — это уже упомянутый PFR и показатель “добровольно кладет деньги в банк”, VP$IP. Он обозначает частоту, с которой человек играет руку при первой возможности сделать ставку или сбросить. Эти два показателя и их соотношение дают мне нужную информацию, чтобы определить, является игрок победителем (акулой) или проигравшим (рыбой).
Принцип Парето утверждает, что для многих событий 80% эффекта приходит от 20% усилий. Это значит, что 80% прибыли компании генерируется 20% их клиентов, а 80% моей прибыли генерируется от 20% моих оппонентов.
Я вычислил 20% противников, у которых я выигрываю чаще всего (рыбы), и 20% противников, которым я чаще всего проигрываю (акулы). Я создал k-means модель с пятью кластерами, чтобы сегментировать оппонентов, используя восемь показателей в качестве переменных. Я идентифицировал сегмент с наибольшей концентрацией рыб и сегмент с наибольшей концентрацией акул. Для каждого сегмента я вычислил средние значения VP$IP и PFR. Я хотел проверить гипотезу о том, что у акул эти показатели будут близки к моим, а у рыб будет наибольший VP$IP и самая крупная разница между двумя показателями.
Акулы


VP$IP = 15.1%

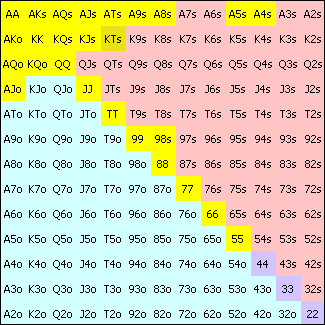
PFR = 11.7%
В сегменте акул оппоненты в среднем имели VP$IP около 15.1% и PFR около 11.7%. На изображении желтым выделены руки, которые игроки обычно играют. Как вы видите, изображения похожи и состоят преимущественно из хороших комбинаций. Эти игроки понимают две вещи:
- Нет смысла класть деньги в банк, если у вас нет хорошей стартовой комбинации, поэтому лучше сбросить.
- Если у вас хорошая стартовая рука, то лучше играть агрессивно и повышать ставки. Агрессивная игра лучше пассивной, потому что повышение ставок дает вам два пути победы: либо у вас будет лучшая комбинация, либо ваши оппоненты сбросят карты. Вторая ситуация не случится, если вы не повышаете ставку.
Эти игроки выигрывают мои деньги, но как это можно применить к компании? Предположим, у нас есть онлайн-магазин. Мы можем узнать многое о наших потенциальных покупателях, отследив, какие страницы нашего сайта они посмотрели. Это даст нам модель поведения. Сегмент, который показывает ограниченный набор страниц с дешевыми товарами, будет состоять из платящих немного или неплатящих клиентов. В будущем мы сможем не тратить на них ресурсы.
Рыбы
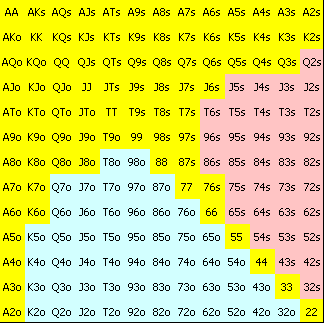
VP$IP = 43.8%
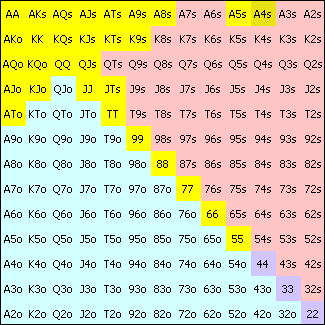
PFR = 14%
В сегменте рыб оппоненты имели VP$IP около 43.8% и PFR в 14%. Эти изображения непохожи. Игроки из этого сегмента добровольно кладут деньги в банк в три раза чаще акул. Это показывает, что они играют посредственные или плохие стартовые комбинации и, что хуже, играют их пассивно. Пассивная игра плохих рук стоит им денег, которые идут в мой карман. Я никогда не был за столом, за которым не играло бы минимум две рыбы.
Давайте вернемся к нашей аналогии с магазином. Как будет выглядеть их ценный сегмент? Люди, которые просматривают много страниц с дорогостоящими товарами. Они могут приходить на сайт через определенные посты в блоге или лендинги. На них может указывать даже время, проведенное на сайте. Как только мы вычислим этих потенциальных клиентов, мы сможем перераспределить ресурсы на них, чтобы сконвертировать их в покупателей, добавив их в таргетированную кампанию или связавшись с ними.
Я обнаружил, что игра в покер — это миниатюра жизни. За свою карьеру я узнал несколько принципов, которыми хочу поделиться с вами:
- Все люди думают, что отлично играют в покер, но на самом деле они ужасны. Когда вы зарабатываете деньги на лжи других людей самим себе, вы понимаете, что все лгут сами себе. Сложно быть честным с собой и окружающими, но это того стоит.
- Вы всегда виноваты. Чтобы стать лучше в покере, вы должны стать самокритичными. Вы не можете научиться на своих ошибках, если будете винить в них других людей. Если вы неудачно составили презентацию, уделите время, чтобы понять, что вы сделали не так и не повторяйте эту ошибку.
- Делайте решения на основе логики, а не на основе эмоций и эгоизма. Они могут вам стоить много денег.
- В играх, связанных с удачей и навыками, выигрывают те, кто собирает информацию и эффективно её использует. Сделайте свою домашнюю работу и уделите время, чтобы больше узнать о компании, с которой у вас будет собеседование, и о менеджере, который будет проводить интервью.
- Не будьте пассивны. Лучшая стратегия — селективная агрессия. За покерным столом это значит повышать ставки с хорошими комбинациями и иногда блефовать, а не просто пассивно пропускать ход. В бизнесе это означает предлагать продажу при отправке предложения, а не просто отправлять предложение и ждать, пока сделка закроется сама собой. Удача улыбается смелым.
P.S. Если вам интересно, из 387,373 сыгранных мной рук мой VP$IP составил 15.6%, а PFR — 12.2%. Вы можете посмотреть на код, который я написал для сегментации своих оппонентов здесь.