Новости
Google открыл ИИ, который умеет находить ответы в таблицах
Google сегодня открыл модель машинного обучения, которая может отвечать на вопросы на естественном языке, основываясь на электронных таблицах и базах данных.
Google сегодня открыл модель машинного обучения, которая может отвечать на вопросы на естественном языке (например, «Какой боксер имел наибольшее количество побед?»), основываясь на электронных таблицах и базах данных. Создатели модели утверждают, что она способна находить даже ответы, распределенные по ячейкам или для которых может потребоваться объединение нескольких ячеек.
Большая часть информации в мире хранится в виде таблиц, отмечает Томас Мюллер из Google Research. Например, мировая финансовая статистика и спортивные результаты. Но этим таблицам часто не хватает интуитивно понятного способа их просмотра — проблема, которую и пытается решить модель искусственного интеллекта Google.
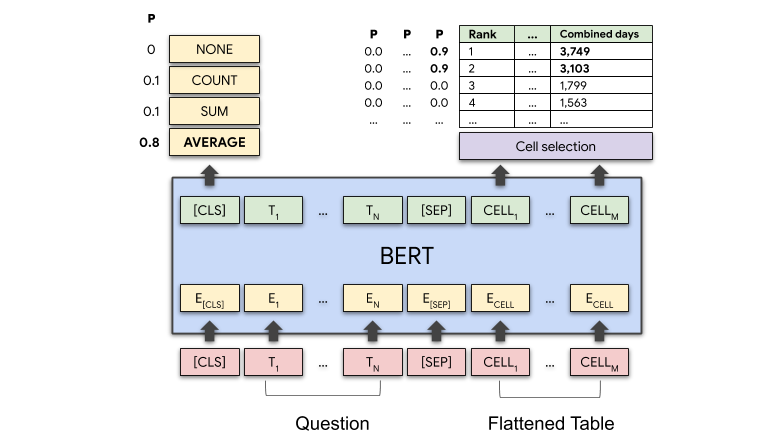
Для обработки вопросов модель кодирует вопрос, а также все содержание таблицы, строка за строкой. Она использует архитектуру BERT на основе трансформатора — архитектуру, которая является как двунаправленной (позволяющей получать доступ к контенту как позади, так и спереди), так и самообучаемой (то есть она может принимать данные, которые не классифицированы и не помечены). Эта архитектура была расширена числовыми представлениями, называемыми вложениями, для кодирования структуры таблицы.
По словам Мюллера, ключевым дополнением были как раз вложения, используемые для понимания структурированного ввода. Вложения для индекса столбца, индекса строки и одного специального индекса ранга указывают модели порядок элементов в числовых столбцах.
Для каждой ячейки таблицы модель генерирует оценку, указывающую вероятность того, что ячейка будет частью ответа. Кроме того, она производит операции (например, «AVERAGE», «SUM» или «COUNT»), указывающие на то, какая операция (если есть) должна быть применена для получения окончательного ответа.

Для предварительной подготовки модели исследователи извлекли 6.2 миллиона пар таблица-текст из английской Википедии, которая послужила набором данных для обучения. Во время предварительного обучения модель, с относительно высокой точностью, научилась восстанавливать слова в таблицах и в текстах, которые были удалены — 71.4% элементов были восстановлены правильно для таблиц, не присутствующих в обучении.
После предварительного обучения Мюллер и его команда провели тонкую настройку модели с помощью слабого контроля, используя ограниченные источники для подачи сигналов для маркировки данных обучения. Они сообщают, что лучшая модель превзошла современного лидера для Sequential Answering Dataset, созданного в Microsoft теста для исследования задач ответов на вопросы в таблицах. Она также обогнала предыдущую лучшую модель WikiTableQuestions Стэнфорда, которая дает ответы на вопросы по таблицам из Википедии.









