Новости
Anthropic запустил инструмент Code Review для проверки ИИ-кода
В центре внимания — исправление логических ошибок, а не стилистических.
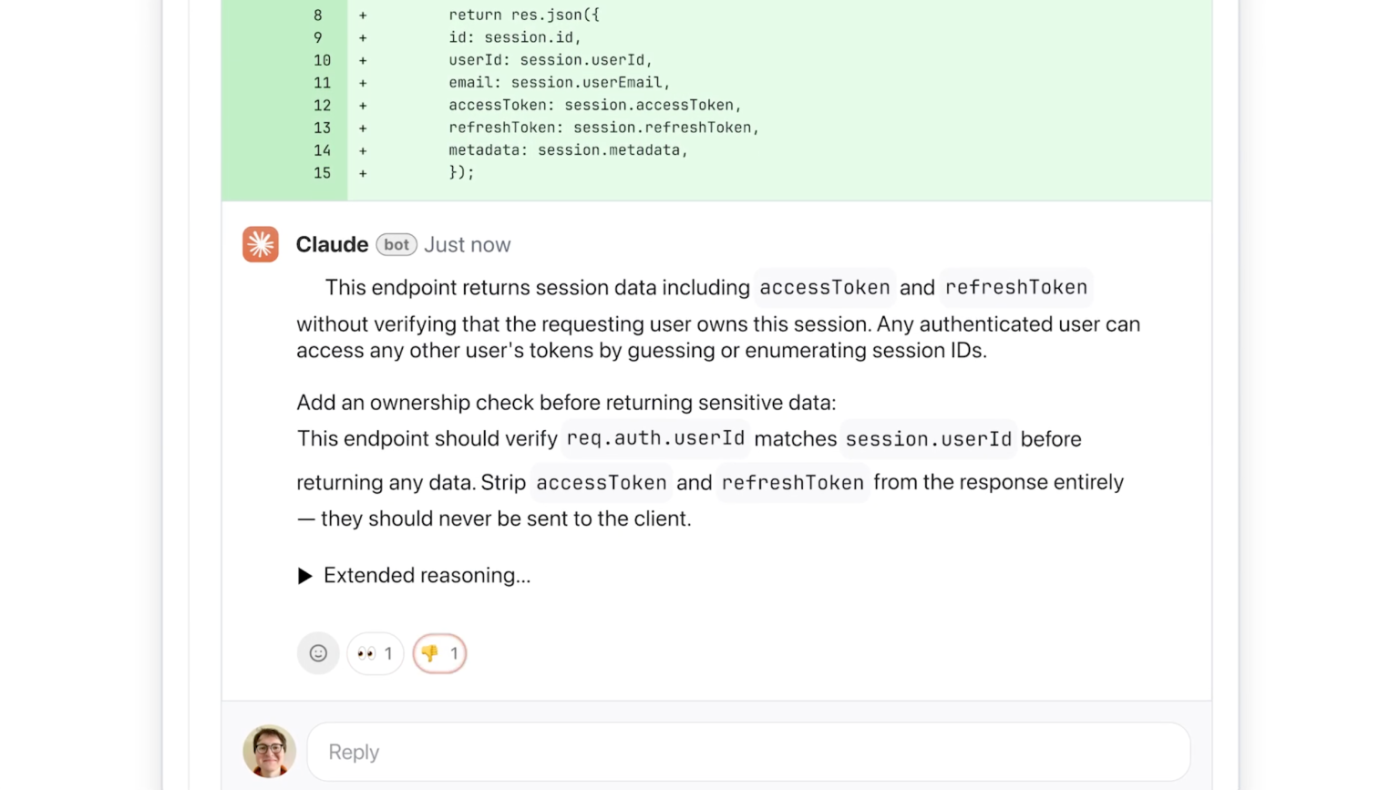
В программировании обратная связь от коллег имеет решающее значение для раннего выявления ошибок, поддержания согласованности кодовой базы и повышения общего качества программного обеспечения.
Распространение вайб-кодинга — использования инструментов искусственного интеллекта, которые принимают инструкции, заданные простым языком, и быстро генерируют большие объемы кода, — изменило подход разработчиков к работе. Хотя эти инструменты ускорили разработку, они также привели к появлению новых ошибок, рисков безопасности и плохо понятого кода.
Решение Anthropic — это другой инструмент проверки кода на основе ИИ, предназначенный для выявления ошибок до того, как они попадут в кодовую базу. Новый продукт под названием Code Review был запущен в понедельник в Claude Code.
«Мы наблюдаем значительный рост популярности Claude Code, особенно в корпоративном секторе, и один из вопросов, который нам постоянно задают руководители предприятий: теперь, когда Claude Code создает множество запросов на слияние , как мне убедиться, что они эффективно проверяются?» — сказала Кэт Ву, руководитель отдела продуктов Anthropic.
Ву отметила, что Claude Code значительно увеличил объем выпускаемого кода, что привело к увеличению количества проверок запросов на слияние, которые создавали узкое место в процессе выпуска кода.
«Code Review — это наш ответ на это», — сказал Ву.
Запуск Code Review от Anthropic — сначала для клиентов Claude for Teams и Claude for Enterprise в режиме предварительного тестирования — происходит в решающий момент для компании. В понедельник компания Anthropic подала два иска против Министерства обороны в ответ на то, что ведомство признало Anthropic «риском для цепочки поставок». Вероятно, в результате этого спора Anthropic будет больше полагаться на свой бурно развивающийся корпоративный бизнес, количество подписок на который с начала года увеличилось в четыре раза. По данным компании, с момента запуска выручка Claude Code превысила 2,5 миллиарда долларов.
«Этот продукт в значительной степени ориентирован на наших крупных корпоративных пользователей, таких как Uber, Salesforce, Accenture, которые уже используют Claude Code и теперь хотят получить помощь в обработке огромного количества [пул реквестов], которые он помогает генерировать», — сказала Ву.
Она добавила, что руководители разработчиков могут включить проверку кода по умолчанию для каждого инженера в команде. После включения она интегрируется с GitHub и автоматически анализирует запросы на слияние, оставляя комментарии непосредственно к коду, объясняя потенциальные проблемы и предлагая решения.
В центре внимания — исправление логических ошибок, а не стилистических, отметила Ву.
«Это действительно важно, потому что многие разработчики уже сталкивались с автоматизированной обратной связью от ИИ, и их раздражает, когда она не сразу применима на практике», — сказал Ву. «Мы решили сосредоточиться исключительно на логических ошибках. Таким образом, мы выявляем наиболее важные проблемы, требующие исправления».
ИИ пошагово объясняет свои рассуждения, описывая, в чем, по его мнению, заключается недостаток, почему он может быть проблемой и как его можно потенциально исправить. Система будет обозначать серьезность проблем цветами: красный — наивысшая серьезность, желтый — потенциальные проблемы, требующие проверки, и фиолетовый — проблемы, связанные с существующим кодом или историческими ошибками.
Ву сказал, что это делается быстро и эффективно за счет параллельной работы нескольких агентов, каждый из которых анализирует кодовую базу с разных точек зрения или в разных аспектах. Последний агент агрегирует и ранжирует результаты, удаляя дубликаты и определяя приоритетность наиболее важных проблем.
Инструмент обеспечивает поверхностный анализ безопасности, а руководители инженерных групп могут настраивать дополнительные проверки на основе внутренних передовых методов. Ву отметила, что недавно запущенный компанией Anthropic инструмент Claude Code Security обеспечивает более глубокий анализ безопасности.
По словам Ву, многоагентная архитектура означает, что этот продукт может быть ресурсоемким. Как и в других сервисах ИИ, ценообразование основано на токенах, и стоимость варьируется в зависимости от сложности кода — хотя Ву оценила стоимость каждой проверки в среднем в 15–25 долларов. Она добавила, что это премиальный и необходимый сервис, поскольку ИИ-инструменты генерируют все больше и больше кода.
«Code Review — это то, что пользуется невероятным спросом на рынке», — сказала Ву. «По мере того, как инженеры разрабатывают с помощью Claude Code, они видят, как снижается сложность создания новых функций, и видят гораздо больший спрос на проверку кода. Поэтому мы надеемся, что с помощью этого мы позволим предприятиям создавать продукты быстрее, чем когда-либо прежде, и с гораздо меньшим количеством ошибок, чем когда-либо прежде».


-

 Интервью4 недели назад
Интервью4 недели назадМаркетологи в мобайле: Анастасия Луканова (руководитель направления по развитию рекламного бизнеса RuStore)
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.26
-

 Магазины приложений4 недели назад
Магазины приложений4 недели назадApple просто убила App Store
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.27