API
Используем бесплатный Moderation API от OpenAI в Swift
Интеграция Moderation API от OpenAI позволяет сбалансировать доступность контента и безопасность пользователей, гарантируя, что ваше приложение останется функциональным и ответственным.
Поскольку большие языковые модели (LLM) становятся все более открытыми и неподверженными цензуре, а пользователи находят способы обойти их ограничения, крайне важно обеспечить соответствие вводимых пользователем данных ценностям и рекомендациям вашего приложения. Внедрение надежной модерации помогает поддерживать целостность вашей платформы и обеспечивает безопасную и уважительную среду для всех пользователей.
Gemini API от Google включает в себя настраиваемые параметры безопасности, предназначенные для фильтрации контента по таким категориям, как преследования, разжигание ненависти, материалы сексуального характера, опасный контент и гражданская порядочность. По умолчанию эти настройки блокируют контент со средней или высокой вероятностью небезопасности. Однако многие разработчики и пользователи посчитали эти фильтры чрезмерно агрессивными, поскольку они часто помечают безвредный контент как небезопасный.
Однако отключение этих фильтров безопасности увеличивает риск подвергания пользователей воздействию вредоносного контента. Чтобы смягчить эту ситуацию, рассмотрите возможность внедрения внешней системы модерации. OpenAI предлагает бесплатный API модерации, который может определять потенциально вредоносный контент в тексте и изображениях, позволяя вам предпринимать корректирующие действия, такие как фильтрация контента или вмешательство в учетные записи пользователей, ответственных за оскорбительный материал.
Интеграция Moderation API от OpenAI позволяет сбалансировать доступность контента и безопасность пользователей, гарантируя, что ваше приложение останется функциональным и ответственным.
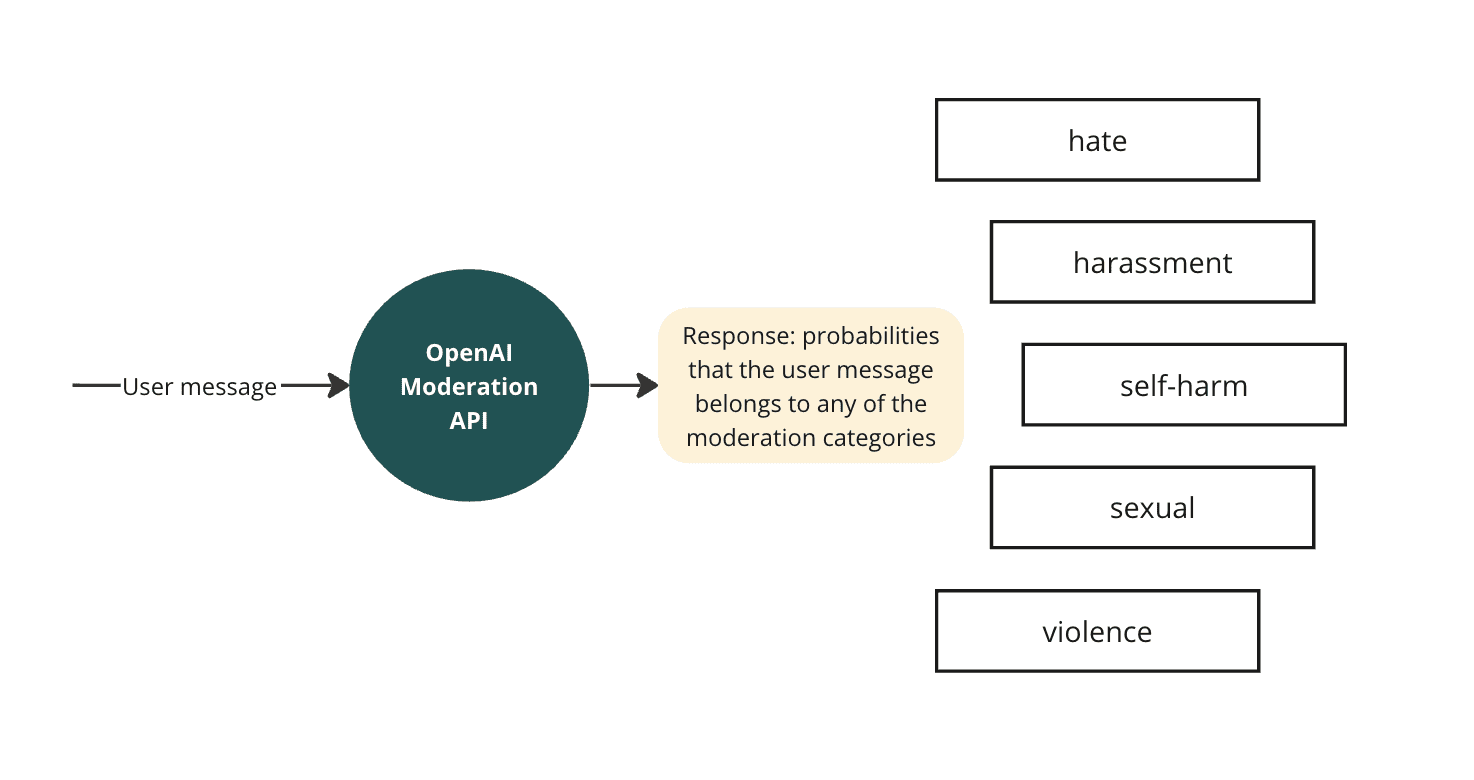
API модерации OpenAI поставляется с двумя моделями:
omni-moderation-latest: эта модель и все снепшоты поддерживают больше вариантов категоризации и мультимодальных входных данных.text-moderation-latest(устаревшая версия): старая модель, которая поддерживает только текстовые входные данные и меньшее количество категорий входных данных. Новые модели всеобъемлющей модерации станут лучшим выбором для новых приложений.
API прост — просто передайте введенный пользователем текст или изображение. Это можно сделать через конечную точку Create Moderations или через библиотеку AIProxySwift следующим образом:
import AIProxy
/* Uncomment for BYOK use cases */
// let openAIService = AIProxy.openAIDirectService(
// unprotectedAPIKey: "your-openai-key"
// )
/* Uncomment for all other production use cases */
// let openAIService = AIProxy.openAIService(
// partialKey: "partial-key-from-your-developer-dashboard",
// serviceURL: "service-url-from-your-developer-dashboard"
// )
let requestBody = OpenAIModerationRequestBody(
input: [
.text("is this bad"),
],
model: "omni-moderation-latest"
)
do {
let response = try await openAIService.moderationRequest(body: requestBody)
print("Is this content flagged: \(response.results.first?.flagged ?? false)")
//
// For a more detailed assessment of the input content, inspect:
//
// response.results.first?.categories
//
// and
//
// response.results.first?.categoryScores
//
} catch AIProxyError.unsuccessfulRequest(let statusCode, let responseBody) {
print("Received \(statusCode) status code with response body: \(responseBody)")
} catch {
print("Could not perform moderation request to OpenAI")
}
Модель вернет следующий объект JSON:
{
"id": "modr-0d9740456c391e43c445bf0f010940c7",
"model": "omni-moderation-latest",
"results": [
{
"flagged": true,
"categories": {
"harassment": true,
"harassment/threatening": true,
"sexual": false,
"hate": false,
"hate/threatening": false,
"illicit": false,
"illicit/violent": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"self-harm": false,
"sexual/minors": false,
"violence": true,
"violence/graphic": true
},
"category_scores": {
"harassment": 0.8189693396524255,
"harassment/threatening": 0.804985420696006,
"sexual": 1.573112165348997e-6,
"hate": 0.007562942636942845,
"hate/threatening": 0.004208854591835476,
"illicit": 0.030535955153511665,
"illicit/violent": 0.008925306722380033,
"self-harm/intent": 0.00023023930975076432,
"self-harm/instructions": 0.0002293869201073356,
"self-harm": 0.012598046106750154,
"sexual/minors": 2.212566909570261e-8,
"violence": 0.9999992735124786,
"violence/graphic": 0.843064871157054
},
"category_applied_input_types": {
"harassment": [
"text"
],
"harassment/threatening": [
"text"
],
"sexual": [
"text",
"image"
],
"hate": [
"text"
],
"hate/threatening": [
"text"
],
"illicit": [
"text"
],
"illicit/violent": [
"text"
],
"self-harm/intent": [
"text",
"image"
],
"self-harm/instructions": [
"text",
"image"
],
"self-harm": [
"text",
"image"
],
"sexual/minors": [
"text"
],
"violence": [
"text",
"image"
],
"violence/graphic": [
"text",
"image"
]
}
}
]
}
Категории модерации следующие:

Ответ Moderation API включает в себя category_scores, которые представляют собой числовые значения в диапазоне от 0 до 1. Эти оценки указывают на уверенность модели в том, что входные данные нарушают политику OpenAI для каждой конкретной категории. Более высокие баллы отражают большую уверенность. Хотя эти оценки предоставляют ценную информацию, важно отметить, что OpenAI может со временем обновлять базовую модель, что может повлиять на эти оценки. Поэтому любые кастомные политики или пороговые значения, основанные на category_scores, могут потребовать периодической перекалибровки для поддержания точности и эффективности.
Интеграция Moderation API OpenAI с Chat Completions API позволяет вашему приложению более эффективно обрабатывать вводимые пользователем данные. Благодаря одновременной работе с обоими API ваша система может оперативно оценивать потенциально опасный контент и реагировать на него. Если API модерации помечает вводимые данные, ваше приложение может реализовать соответствующие меры, например, информировать пользователя о помеченном контенте или применять политики, например правило «трех предупреждений» для повторных нарушителей.


-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.27
-

 Интегрированные среды разработки2 недели назад
Интегрированные среды разработки2 недели назадАналоги Cursor для разработчиков: что выбрать для работы с кодом
-

 Разработка4 недели назад
Разработка4 недели назадApple Container уже здесь, и он изменит ваш подход к iOS-разработке
-

 Разработка3 недели назад
Разработка3 недели назадУ вас осталось всего несколько недель на вайб-кодинг