Исследования
Лучшие ИИ-инструменты для программирования допускают ошибки в каждом четвертом случае
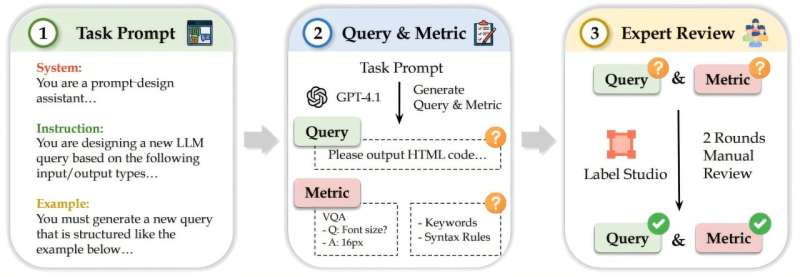
В исследовании оценивались 11 моделей LLM в 18 структурированных форматах вывода и 44 задачах, предназначенных для оценки надежности следования системами структурированным правилам.
Новое исследование Университета Ватерлоо показывает, что искусственный интеллект по-прежнему испытывает трудности с некоторыми базовыми задачами разработки программного обеспечения, что поднимает вопросы о том, насколько надежно системы ИИ могут помогать разработчикам. По мере того, как большие языковые модели все чаще используются в разработке программного обеспечения, разработчики сталкиваются с проблемой обеспечения точности, согласованности и простоты интеграции генерируемых ИИ ответов в более крупные рабочие процессы разработки.
Исследование «StructEval: Оценка возможностей LLM по генерации структурированных выходных данных» опубликовано в журнале Transactions on Machine Learning Research и будет представлено на конференции ICLR 2026.
Ранее LLM отвечали на запросы разработки программного обеспечения в свободной форме на естественном языке. Для решения этой проблемы несколько компаний, занимающихся ИИ, включая OpenAI, Google и Anthropic, ввели «структурированные выходные данные». Эти выходные данные заставляют ответы LLM соответствовать предопределенным форматам, таким как JSON, XML или Markdown, что упрощает их чтение и обработку как для людей, так и для программных систем.
Однако новое исследование, проведенное в Университете Ватерлоо, показывает, что технология пока не так надежна, как надеялись многие разработчики. Даже самые продвинутые модели достигли лишь около 75% точности в тестах, в то время как модели с открытым исходным кодом показали результаты, близкие к 65%.
В исследовании оценивались 11 моделей LLM в 18 структурированных форматах вывода и 44 задачах, предназначенных для оценки надежности следования системами структурированным правилам.
«В подобных исследованиях мы хотим измерить не только синтаксис кода — то есть, следует ли он установленным правилам, — но и точность результатов, полученных для различных задач», — сказал Дунфу Цзян, аспирант в области компьютерных наук и соавтор исследования.
«Мы обнаружили, что, хотя они неплохо справляются с задачами, связанными с текстом, они испытывают серьезные трудности с задачами, связанными с генерацией изображений, видео или веб-сайтов».
Исследование было результатом совместной работы студента Цзялиня Яна из Университета Ватерлоо и доцента кафедры компьютерных наук доктора Вэньху Чена, и включало аннотации от 17 других исследователей из Ватерлоо и со всего мира.
«В последнее время в наших лабораториях проводится много подобных проектов по сравнительному анализу», — сказал Чен. «В Ватерлоо студенты часто начинают как аннотаторы, затем организуют проекты и создают собственные сравнительные исследования. Они не просто используют ИИ в своих исследованиях — они его создают, исследуют и оценивают».
Хотя результаты, структурированные с помощью LLM, являются важным шагом в разработке программного обеспечения, исследователи говорят, что системы пока недостаточно надежны для работы без человеческого контроля. «У разработчиков могут быть эти агенты, работающие на них, но им все равно требуется значительный человеческий контроль», — сказал Цзян.


-

 Аналитика магазинов4 недели назад
Аналитика магазинов4 недели назадМобильный рынок Ближнего Востока: выручка растёт быстрее загрузок: исследование Bidease и Sensor Tower
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.24
-

 Разработка4 недели назад
Разработка4 недели назадОдин файл CLAUDE.md стал вирусным — причина до смешного проста
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.25