Разработка
Проектируем системный дизайн Spotify
Обычно на реальном собеседовании вы сосредоточитесь на одной или двух основных функциональных возможностях приложения, но в этой статье я хотел бы сделать общий обзор того, как вы будете проектировать такую систему, а затем вы сможете углубиться в каждую отдельную часть, если потребуется.
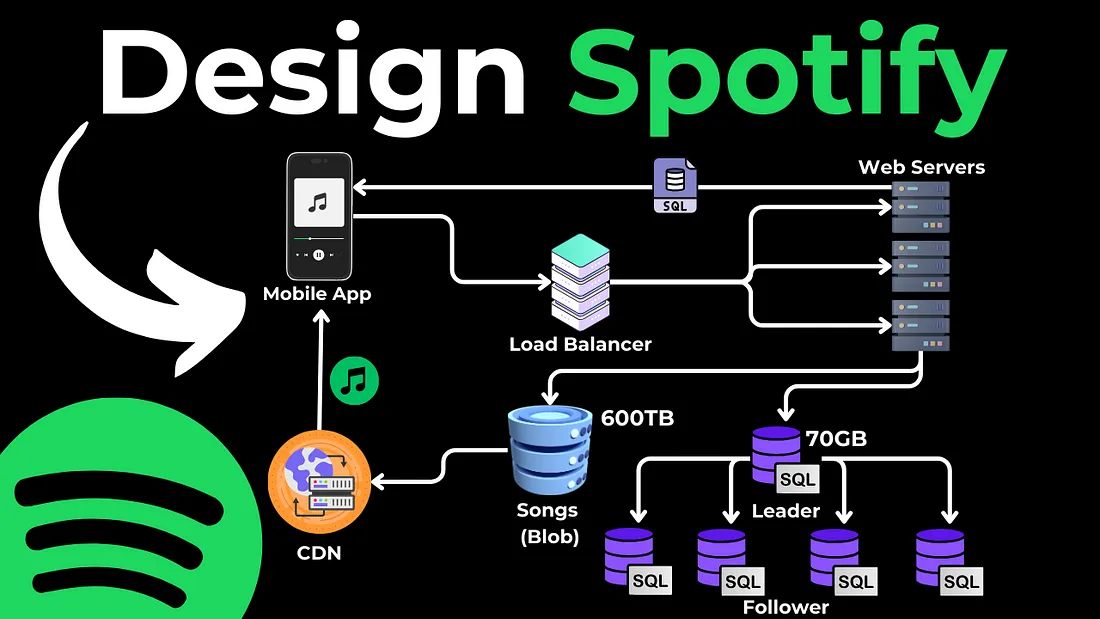
Это вопрос для собеседования по проектированию систем, в котором вам предстоит спроектировать Spotify. Обычно на реальном собеседовании вы сосредоточитесь на одной или двух основных функциональных возможностях приложения, но в этой статье я хотел бы сделать общий обзор того, как вы будете проектировать такую систему, а затем вы сможете углубиться в каждую отдельную часть, если потребуется.
Начальная фаза: базовая версия
Требования: Первоначальное требование — обработка 500 тысяч пользователей и 30 миллионов песен. У нас будут пользователи, которые проигрывают песни, и артисты, которые загружают песни.

Оценка: подсчет данных
Давайте начнем с оценки необходимого нам хранилища. Во-первых, нам нужно хранить песни в каком-то хранилище.
- Хранилище песен: Spotify и подобные сервисы часто используют такие форматы, как Ogg Vorbis или AAC для потоковой передачи, и если предположить, что средний размер песни составляет 3 МБ, нам понадобится 3 МБ * 30 миллионов = 90 ТБ для хранения песен.
- Метаданные песни: Нам также необходимо хранить метаданные песен и информацию о профиле пользователя. Средний размер метаданных одной песни составляет около 100 байт — 100 байт * 30 миллионов = 3 ГБ.
- Метаданные пользователей: В среднем мы будем хранить 1 КБ данных на пользователя — 1 КБ * 500 000 = 0,5 ГБ.

Высокоуровневый дизайн
Мобильное приложение: У нас будет мобильное приложение, которое является фронтендом, через который пользователи взаимодействуют с сервисом. Пользователи могут искать песни, воспроизводить музыку, создавать плейлисты и т.д. Когда пользователь выполняет действие (например, проигрывает песню), приложение отправляет запрос на внутренние серверы.
Балансировщик нагрузки: Но прежде чем обратиться к серверам, мы используем балансировщик нагрузки, который распределяет входящий трафик между несколькими веб-серверами. Это повышает доступность и отказоустойчивость нашего приложения.

Веб-серверы (API): Веб-серверы — это API, которые обрабатывают входящие запросы от мобильного приложения. Например, если пользователь хочет воспроизвести песню, запрос отправляется на эти веб-серверы. Затем сервер определяет, где находится песня (в базе данных или в службе хранения) и как ее получить.
Хранилище данных
Хранилище данных будет разделено на два отдельных сервиса — Blob Storage для песен, где мы будем хранить фактические файлы песен, и SQL Database, где мы будем хранить метаданные песен и пользователей.

Песни — Blob Storage (например, AWS S3, GCP, Azure Blob Storage): Фактические файлы песен хранятся в службе хранения Blob (Binary Large Object). Эти службы предназначены для хранения больших объемов неструктурированных данных.
Пользователи, исполнители и метаданные песен — база данных SQL: В этой базе данных SQL хранятся структурированные данные, такие как информация о пользователях (например, имена пользователей, пароли и адреса электронной почты) и метаданные о песнях (например, названия песен, имена исполнителей, сведения об альбомах и т. д.).
Почему именно SQL? Базы данных SQL идеально подходят для такого рода структурированных данных, поскольку они позволяют выполнять сложные запросы и устанавливать связи между различными типами данных.
Каждый файл песни хранится в виде «большого бинарного объекта», а в базе данных SQL обычно хранится ссылка на этот файл (например, URL).
Структура базы данных SQL
Вот базовая схема таблиц и связей между ними, которые мы будем иметь в нашей базе данных SQL.
Нам понадобится таблица Users, которая будет содержать метаданные пользователей, такие как UserID, Username, Email, PasswordHash, CreatedAt, LastLogin и т.д.

Таблица Songs будет содержать метаданные песни, такие как SongID, Title, ArtistID, Duration, ReleaseDate и FileURL, который является URL-адресом места, где хранится файл песни (например, в блоб-хранилище).
Таблица Artists будет содержать информацию об исполнителе — ArtistID, имя, биографию, страну и т.д.
Отношения: Мы объединим таблицы Artists и Songs в таблицу ArtistsSongs, где у нас будет ArtistID (внешний ключ, указывающий на таблицу Artists) и SongID (внешний ключ, указывающий на таблицу Songs). Отсюда мы можем получить метаданные песни, которые также будут содержать свойство FileURL, указывающее на Blob-хранилище, где находится песня.
Собираем все вместе

Итак, веб-сервер получит метаданные песни из базы данных SQL, а из метаданных песни — URL файла, который затем будет транслироваться с сервера порция за порцией в мобильное приложение. Или мы можем напрямую передавать их из объектного хранилища клиенту, минуя веб-сервер, чтобы снизить нагрузку.
Фаза масштабирования: 50 млн пользователей, 200 млн песен
А что, если мы увеличим количество пользователей до 50 миллионов и 200 миллионов песен? Сначала нам нужно пересчитать данные. Это означает, что в хранилище данных SQL нужно хранить в 200/30 = ~6,66 раз больше метаданных песен:
100 байт на песню * 200 миллионов песен = 20 ГБ.
То же самое касается метаданных о пользователях:
1 КБ на пользователя * 50 миллионов пользователей = 50 ГБ.

Внедрение CDN
Поскольку трафик увеличился, нам нужно внедрить кэширование и CDN (например, Cloudfront/Cloudflare), который будет обслуживать песни, и каждый CDN будет географически близок к одному региону, следовательно, она сможет обслуживать песни быстрее, чем веб-сервер.

Мы можем использовать политику вытеснения LRU (Least Recently Used) для кэширования популярных песен, а непопулярные песни будут по-прежнему извлекаться из хранилища Blob и затем кэшироваться в CDN.
Файлы песен также могут напрямую передаваться из облачного хранилища клиенту, что снизит нагрузку на веб-серверы.
Масштабирование базы данных: техника «лидер-последователь»
База данных также нуждается в расширении. Поскольку мы знаем, что наше приложение получает гораздо больше чтений, чем записей, то есть пользователей, слушающих песни, много, а исполнителей, загружающих песни, относительно мало, мы можем использовать технику Leader → Follower и иметь одну базу данных Leader, которая будет принимать чтения/записи, и несколько баз данных Follower или Slave, которые будут доступны только для чтения, чтобы получать метаданные песен и пользователей.

При необходимости мы также можем реализовать шардинг базы данных и разделить ее на несколько баз данных или реализовать технику Leader ↔ Leader, но это более сложные сценарии, и вы не встретите интервью, где вас будут спрашивать об этом слишком подробно.
Если вы хотите узнать больше о каждом компоненте, который мы здесь обсудили, у меня есть подробный туториал «Концепции собеседования по системному дизайну», где я рассказываю о каждом из них более подробно.
Дополнительно
- System Design Course: курс по системному дизайну
- Мок-собеседование по Android System Design
- Публичное собеседование по System design


-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.27
-

 Интегрированные среды разработки2 недели назад
Интегрированные среды разработки2 недели назадАналоги Cursor для разработчиков: что выбрать для работы с кодом
-

 Разработка4 недели назад
Разработка4 недели назадApple Container уже здесь, и он изменит ваш подход к iOS-разработке
-

 Разработка4 недели назад
Разработка4 недели назадУ вас осталось всего несколько недель на вайб-кодинг