Разработка
Создание комплексной системы ведения JSON логов для клиентских приложений Pinterest
Поскольку этот пайплайн можно использовать без каких-либо реальных усилий, разработчики активно стали внедряли эту систему ведения журналов для множества задач.
В начале 2020 года во время критического инцидента с нехваткой памяти на iOS (об этом у нас есть статья в блоге) мы поняли, что у нас недостаточно информации о том, как работают приложения, или хорошей системы для поиска и устранения неполадок.
Состояние логов
В то время в клиентских приложениях было несколько способов логирования повседневной работы:
- Контекстное логирование: создано для регистрации данных и построения и отчетов о показах или всего, что связано с бизнесом, поэтому основано на критической ко времени и первоклассной конечной точке. Разработчикам необходимо было явно определять ключи, которые в противном случае были бы отклонены конечной точкой. Некоторые компании называют это «аналитическим логированием».
- Разное: запись в локальный файл на диске или даже запись в службу отслеживания сбоев о типе ошибки.
Проблемы
- Не все логи попадали в эти категории, и люди часто злоупотребляли определенными типами логирования.
- Ни один из этих инструментов не обеспечивал хорошего способа визуализации или агрегирования. Например, разработчикам необходимо было внести изменения в код, чтобы получить такую информацию — «как выглядит метрика в версии приложения A на устройстве B и в сети типа C».
- Не существовало системы, которая может легко отслеживать логи в режиме реального времени, не говоря уже о создании системы оповещения в реальном времени о пользовательских метриках на основе логов.
Цель
Мы решили создать сквозной конвейер со следующими характеристиками:
- Он построен на наименьшем сопротивлении: полезные данные логов не имеют схемы и являются гибкими, в основном это пары ключ-значение. Это одна из причин, по которой мы называем это JSON логированием.
- Он готов к использованию API-интерфейсов ведения логов на каждой платформе.
- Разработчикам не нужно трогать какие-либо бэкэнд-системы.
- Легко запрашивать и визуализировать логи.
- Работает в режиме реального времени!
С учетом этого были приняты следующие ключевые проектные решения:
- Конечная точка службы ведения логов будет выполнять валидацию, парсинг и обработку журналов.
- Логи будут храниться в улье, что позволит поддерживать любые запросы на основе SQL.
- Единая и общая тема Kafka будет использоваться для всех журналов, проходящих через этот конвейер.
- Он интегрирован с OpenSearch (форк Elasticsearch и Kibana от Amazon) в качестве инструмента визуализации и запросов в реальном времени.
- Будет легко настроить оповещения в режиме реального времени с помощью кастомных метрик на основе логов.
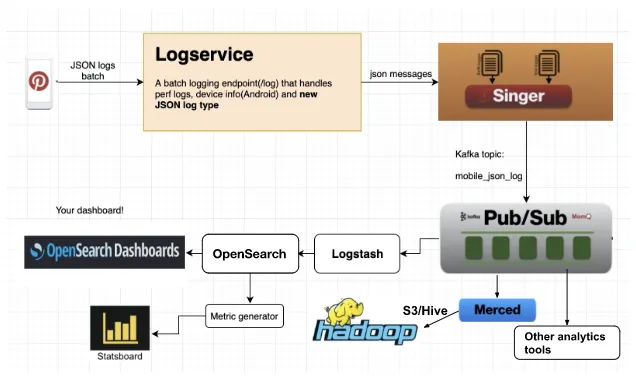
Архитектура
На высоком уровне

Схема
Интеграция на стороне клиента со службой определяется метаданными, а разработчикам просто нужно указать имя лога и фактическую полезную нагрузку. Больше ничего не требуется.
Пример полезной нагрузки:

Визуализация и запросы
Визуализация логов в Opensearch относительно проста, можно просто следовать инструкциям, предоставленным для этого конвейера. Кроме того, разработчики могут использовать SQL-запросы и любые другие инструменты запросов/визуализации, поддерживаемые этим конвейером, для выполнения запросов.

Оповещения в режиме реального времени
Метрики на основе логов — это экономичный способ суммировать данные всего входного потока. С помощью log-based метрик разработчики могут генерировать количественные метрики, соответствующие Lucene-запросам. Для более продвинутых вариантов использования можно создавать метрики из запроса агрегации терминов OpenSearch, чтобы анализировать данные логов в различных измерениях.

Метрики на основе логов можно использовать для создания дашбордов и оповещений в реальном времени:

Примеры использования
Поскольку этот пайплайн можно использовать без каких-либо реальных усилий, разработчики активно стали внедряли эту систему ведения журналов для множества задач.
Видимость клиентов
- Получение сетевых метрик и метрики сбоев, чтобы лучше понимать, как работают клиенты и передавать эти клиентские сигналы на стороне клиента в главную метрику Pinner Uptime.
- Анализ производительности, например на основе информации, предоставленной iOS MetricKit.
- Создание кастомных отчетов об ошибках, таких как исключения, программные ошибки и утверждения, которые ранее либо не сообщались, либо сообщались где-то и не имели хорошего инструмента для анализа.
Продукт/работа фич
- Некоторые продуктовые команды используют эту систему для создания отчетов о работе функций продукта, таких как результаты создания пинов, чтобы они могли отслеживать показатели успеха/неудачи в режиме реального времени. Это часто выявляет проблемы намного раньше, чем обычное ежедневное агрегирование метрик, и это особенно полезно для проблем, о которых мониторинг на стороне API не предупредит сразу.
Логи разработчиков
- Разработчики любят использовать этот конвейер, чтобы получить представление об определенной логике или путях кода в рабочей среде, например. «выполнялся ли когда-нибудь этот код?», «как часто это происходит?» и многие подобные вопросы, на которые могут ответить только данные.
- Разработчики добавляют логи, чтобы помочь устранить странные ошибки, которые очень трудно воспроизвести локально, или найти проблемы, возникающие только на определенных моделях устройств, версиях ОС и т.д.
Оповещение в режиме реального времени
- Из-за простоты настройки отчетов и оповещений команды продуктовых разработчиков часто используют их только для оповещений в реальном времени.
Будущее
- На стороне Opensearch мы хотим создать индексы подуровня по именам, что может повысить производительность запросов, а также лучше изолировать журналы.
- Хотим изучить функцию оповещения, предоставляемую Opensearch


-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.27
-

 Интегрированные среды разработки2 недели назад
Интегрированные среды разработки2 недели назадАналоги Cursor для разработчиков: что выбрать для работы с кодом
-

 Разработка4 недели назад
Разработка4 недели назадУ вас осталось всего несколько недель на вайб-кодинг
-

 Разработка4 недели назад
Разработка4 недели назадМиграция приложения на Navigation 3: боль, переработки и хотфиксы