Автоматическое тестирование приложений
Как я использую мутационное тестирование для поддержки хорошего покрытия тестами
Тестирование — важная часть разработки программного обеспечения, а хороший автоматизированный набор тестов позволяет выявить ошибки за считанные минуты. Автоматизированные тесты обычно запускаются в рамках непрерывной интеграции, которая выполняется на отдельной машине без особого участия разработчика.
Сравните это с ручным тестированием, при котором обычно собирается все приложение, требуется пройтись по нему, иногда даже изменить сетевые ответы, чтобы проверить крайние случаи (например, ошибки, недостающие данные). Все эти ручные действия, выполняемые в течение дня, довольно быстро накапливаются (не говоря уже обо всем времени жизни проекта) и стоят разработчикам много времени, которое можно было бы потратить на другое.
Однако, чтобы иметь хороший набор автоматизированных тестов, он должен охватывать все граничные случаи для важных частей кода. Важным кодом может быть только сложная логика, к которой все боятся прикасаться, опасаясь ее сломать. Это также может быть код, который часто изменяется и при небольшом недосмотре может привести к регрессиям (т.е. ошибкам).
К сожалению, иметь хороший набор тестов не так-то просто, каждый разработчик должен быть усердным и добавлять тесты для каждого логического условия. Если автор забывает это сделать, то рецензент кода должен заметить это и поднять недостающие тестовые случаи.
Хорошей новостью является то, что мутационное тестирование — это подход, который позволяет быстро найти недостающие тестовые случаи.
Что такое мутационное тестирование
Говоря простым языком, мутационное тестирование подразумевает изменение рабочего кода и последующий запуск тестов. Если после этого изменения происходит сбой, то обычно это условие покрывается тестами (иногда даже если какой-то тест не проходит после «мутации», полезно перепроверить, что тест не проходит по правильным причинам — например, тест нацелен на какую-то другую часть производственного кода, но не срабатывает как побочный эффект этой мутации). Однако если все тесты проходят, то, скорее всего, для этого условия тоже не хватает тестового случая.
Пример граничных значений
Взгляните на этот пример производственного кода:
enum class Priority {
LOW,
HIGH,
}
fun convertToPriority(value: Int): Priority? {
if (value !in 0..100) return null
return if (value <= 100 && value > 50) {
Priority.HIGH
} else {
Priority.LOW
}
}
Логику можно было бы упростить, но я хотел оставить ее в таком виде, чтобы смоделировать большое количество условий, которые может быть сложно протестировать. В приведенном выше коде скрыты некоторые ошибки, которые текущий набор тестов не обнаруживает:
@Test
fun `When value is -1 then null is returned`() {
convertToPriority(-1) shouldBe null
}
@Test
fun `When value is 101 then null is returned`() {
convertToPriority(101) shouldBe null
}
@Test
fun `When value is 51 then High priority is returned`() {
convertToPriority(51) shouldBe Priority.HIGH
}
@Test
fun `When value is 50 then Low priority is returned`() {
convertToPriority(50) shouldBe Priority.LOW
}
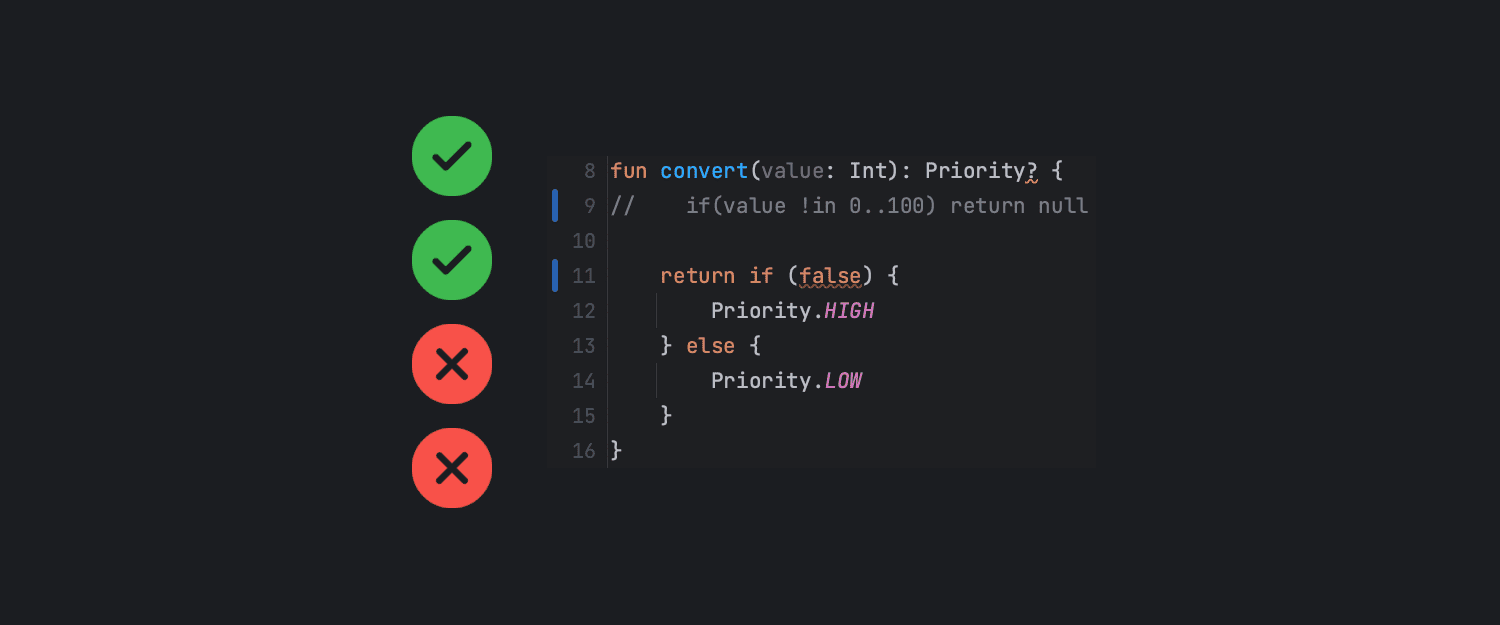
Глядя на приведенные выше тестовые примеры, может показаться, что все охвачено, однако, когда речь идет о граничных значениях, очень важно проверить их все. В приведенной выше функции граничными значениями являются 100, 50 и 0.
Чтобы найти недостающие тестовые случаи, достаточно просто изменить верхнее граничное значение на меньшее, например 99:
![]()
В производственном коде 100 рассматривается как высокий приоритет, так что, вероятно, это и есть основа для тестирования. Однако после этого изменения все тесты по-прежнему проходят, что означает отсутствие тестового случая для проверки:
@Test
fun `When value is 100 then High priority is returned`() {
convertToPriority(100) shouldBe Priority.HIGH
}
Еще один недостающий тестовый пример — для нижней границы в первом условии:
![]()
Все тесты по-прежнему проходят, поэтому необходимо добавить следующий тест:
@Test
fun `When value is 0 then Low priority is returned`() {
convertToPriority(0) shouldBe Priority.LOW
}
Шпаргалка по мутационному тестированию
Каждое условие, например if, фильтры или все, что использует булеву величину, можно легко изменить:
- Закомментировав его вообще (удалив ветвь условия)
- Изменив граничные значения в сравнениях (как в примере выше)
- Изменив условия (например, с помощью
!,.not()или переключения сanyнаall)
Другими мутациями кода может быть возврат жестко закодированного значения (например, пустого списка, ошибки или null).
Почему покрытие кода не говорит всей правды
Покрытие кода — это обманчивая метрика, посмотрите на этот пример:

Глядя на приведенный выше результат, кажется, что все покрыто, однако, как уже отмечалось ранее, в приведенном выше коде есть проблемы с граничными значениями. Поэтому, несмотря на то, что все строки покрыты тестами, набор не является полным и пропускает некоторые случаи.
Покрытие можно использовать только для проверки строк кода, однако для сложных условий оно может ввести в заблуждение и дать ложную уверенность в том, что все случаи покрыты.
Написание кода
Когда я пишу код, то чаще всего использую Test Driven Development, что на практике должно означать, что нет ни одного продакшн-кода, для которого не было бы соответствующего теста.
Бывают случаи, когда я не использую TDD, или логика настолько сложна, что я не смог придумать все тестовые случаи для нее. В таких случаях на помощь приходит мутационное тестирование, поскольку оно позволяет быстро найти недостающие случаи.
Рецензирование кода
Когда я просматриваю код, содержащий тесты, я обычно открываю рабочий код и тесты бок о бок в режиме раздельного просмотра. Сначала я читаю тестовые случаи и пытаюсь понять требования класса.
После проверки существующего кода я пытаюсь найти все недостающие случаи с помощью мутационного тестирования. Благодаря этому мне не нужно тратить много времени на сканирование всех тестовых случаев и проверку соответствующего производственного кода.
Помимо поиска недостающих тестовых случаев, мутационное тестирование может также обнаружить тесты, которые проходят по неправильной причине. Например, в производственном коде используются условия A и B. Тест проверяет, что при выполнении условия A он проходит. Однако при мутационном тестировании условие A удаляется, но тест все равно проходит. Это означает, что тест проходит по неправильной причине и его необходимо изменить.
Резюме
Чтобы убедиться, что что-то правильно протестировано, сначала нужно полностью понять код, а мутационное тестирование — это своего рода короткий путь для этого. Если измененный код не приводит к отказу теста, значит, какой-то тестовый случай отсутствует.
Эта техника полезна для обеспечения хорошего тестового покрытия, но не обязательно использовать ее каждый раз. Есть менее важные классы, которые не нуждаются в идеальном тестовом покрытии.
Основное внимание при использовании мутационного тестирования должно быть уделено коду, который:
- Часто изменяется (потому что изменения могут приводить к регрессиям, а автоматизированные тесты помогают их отлавливать).
- Критичен для функциональности программного обеспечения (наличие тестов для вещей, которые используются только для разработки, может быть излишним).
- Имеет очень сложную логику, что затрудняет внесение изменений без торможения. В таких ситуациях тесты могут действовать как путеводный маяк: если все зелено, то можно приступать.
Если вам интересно узнать больше о тестировании в целом, ознакомьтесь с циклом моих статей на эту тему.


-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.25
-

 Разработка4 недели назад
Разработка4 недели назадЛучшие практики SwiftUI из агентского навыка Xcode 27
-

 Новости4 недели назад
Новости4 недели назадAndroid 17 официально вышел
-

 Интервью3 недели назад
Интервью3 недели назадМаркетологи в мобайле: Анастасия Луканова (руководитель направления по развитию рекламного бизнеса RuStore)