Разработка
Kotlin-bench — тест ИИ-моделей для Android-разработки
В целом, Kotlin-bench предоставляет ценный инструмент для оценки и сравнения возможностей LLM в области разработки на Kotlin и Android, помогая как исследователям, так и практикующим разработчикам принимать обоснованные решения при выборе и использовании языковых моделей.
Kotlin-bench — это специализированный бенчмарк, разработанный для оценки производительности больших языковых моделей (LLM) и AI-агентов в задачах, связанных с реальной разработкой на Kotlin и Android. Цель бенчмарка — предоставить объективный инструмент для сравнения производительности различных LLM в контексте понимания и генерации кода на Kotlin.
Особенности Kotlin-bench
- Основан на реальных задачах: Бенчмарк включает 100 задач, взятых из популярных GitHub-репозиториев, таких как kotlinx.coroutines и Anki-Android. Эти задачи отражают реальные проблемы, с которыми сталкиваются разработчики при работе с Kotlin и Android.
- Объективная оценка решений: Для проверки корректности решений, сгенерированных моделями, используются юнит-тесты соответствующих проектов. Модель считается успешно справившейся с задачей, если её код проходит все тесты, что обеспечивает объективность оценки.
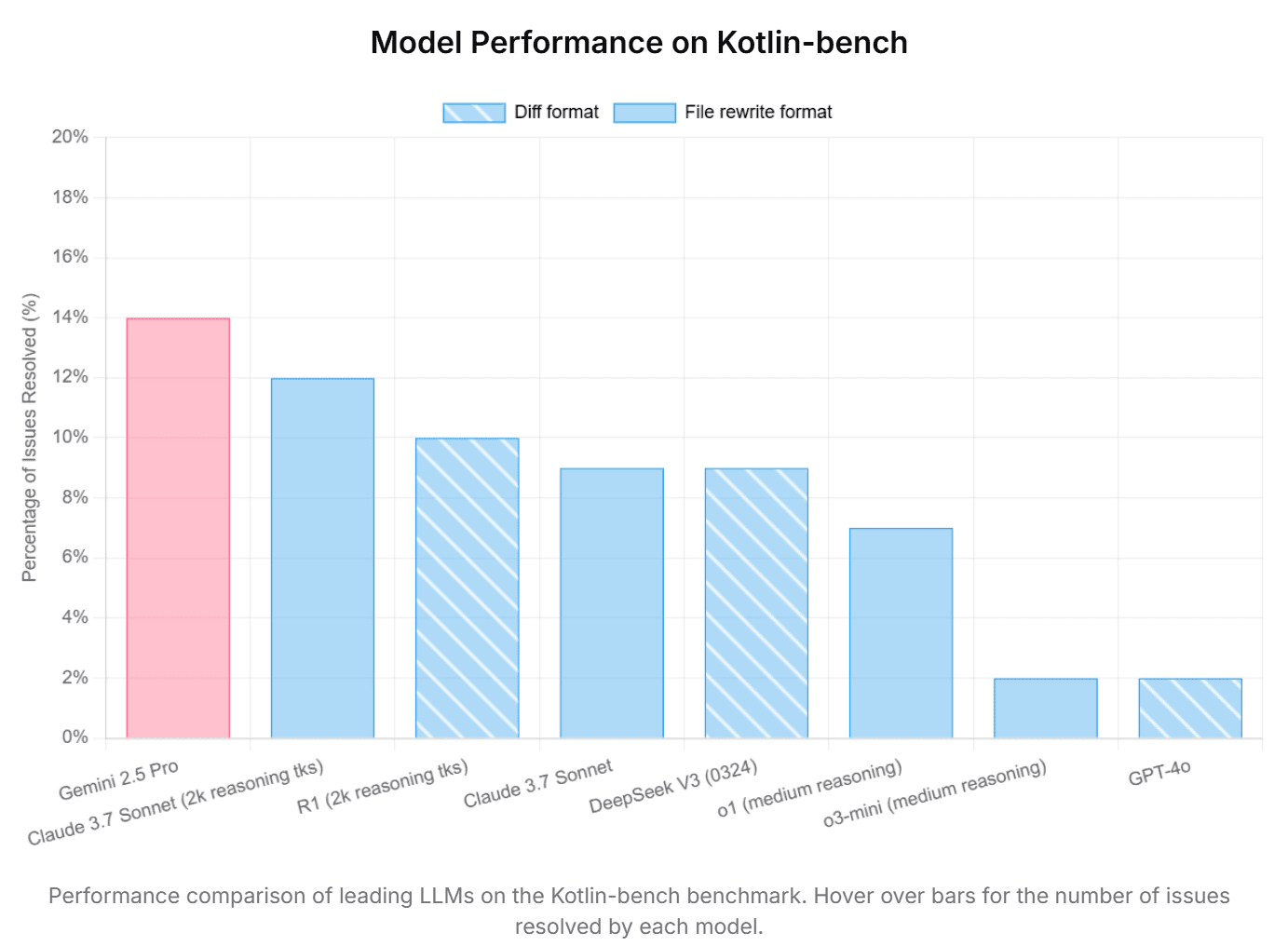
- Сравнение производительности моделей: Kotlin-bench позволяет сравнивать различные LLM по их способности решать задачи, связанные с Kotlin и Android. Например, согласно результатам, модель Gemini 2.5 успешно решила 14% задач, опередив другие модели, такие как Claude 3.7 (режим «thinking») и Deepseek R1.
Преимущества использования Kotlin-bench
- Выбор подходящей модели: Разработчики могут использовать результаты бенчмарка для выбора наиболее эффективной модели для задач, связанных с Kotlin и Android, что способствует повышению производительности и качества разработки.
- Стимулирование улучшений в моделях: Публикация результатов бенчмарка мотивирует разработчиков моделей улучшать их производительность в контексте задач на Kotlin, что способствует развитию экосистемы инструментов для этого языка.
Текущие результаты
На текущий момент бенчмарк Kotlin-bench продемонстрировал следующие результаты при оценке производительности крупных языковых моделей (LLM) в задачах, связанных с разработкой на Kotlin и Android:
- Gemini 2.5: показала наилучший результат, успешно решив 14% задач.
- Claude 3.7 (режим «thinking»): приблизился к результатам Gemini 2.5, также продемонстрировав высокую эффективность.
- Deepseek R1: занял третье место по производительности.
- OpenAI o3-mini: показал менее впечатляющий результат, решив лишь 2% задач.
Эти результаты подчеркивают значительные различия в эффективности различных моделей при решении реальных задач на Kotlin и Android. Особенно примечательно превосходство Gemini 2.5 и моделей в режиме «thinking» над стандартными версиями. Это свидетельствует о важности выбора подходящей модели для конкретных задач разработки
В целом, Kotlin-bench предоставляет ценный инструмент для оценки и сравнения возможностей LLM в области разработки на Kotlin и Android, помогая как исследователям, так и практикующим разработчикам принимать обоснованные решения при выборе и использовании языковых моделей.


-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.27
-

 Интегрированные среды разработки2 недели назад
Интегрированные среды разработки2 недели назадАналоги Cursor для разработчиков: что выбрать для работы с кодом
-

 Разработка4 недели назад
Разработка4 недели назадApple Container уже здесь, и он изменит ваш подход к iOS-разработке
-

 Разработка3 недели назад
Разработка3 недели назадУ вас осталось всего несколько недель на вайб-кодинг