Новости
Anthropic «ослабляет» Claude?
Флагманская модель для программирования стала менее способной, менее надёжной и более «прожорливой» к токенам по сравнению с тем, что было ещё несколько недель назад.
Растущее число разработчиков и продвинутых пользователей ИИ обвиняют Anthropic в ухудшении работы моделей Claude Opus 4.6 и Claude Code — либо намеренно, либо из-за ограничений вычислительных ресурсов. По их словам, флагманская модель для программирования стала менее способной, менее надёжной и более «прожорливой» к токенам по сравнению с тем, что было ещё несколько недель назад.
Жалобы быстро распространились на GitHub, X и Reddit. Пользователи утверждают, что Claude стал хуже справляться с длительным рассуждением, чаще бросает задачи на полпути и склонен к галлюцинациям и противоречиям.
Некоторые называют это «AI shrinkflation» — ситуацией, когда пользователи платят столько же, но получают более слабый продукт. Другие предполагают, что Anthropic может искусственно ограничивать («душить») модель в периоды высокой нагрузки.
Эти утверждения не доказаны, и сотрудники Anthropic публично отрицают намеренное ухудшение моделей для управления нагрузкой. При этом компания признаёт, что в последние недели были реальные изменения лимитов использования и настроек рассуждения, что усилило споры.
Жалобы становятся вирусными — в том числе от топ-менеджера AMD
Одна из самых подробных жалоб появилась 2 апреля 2026 года в GitHub-issue от Стеллы Лауренцо — старшего директора AI-направления в AMD.
Она заявила, что Claude Code деградировал до уровня, при котором ему нельзя доверять сложную инженерную работу. В подтверждение она проанализировала:
- 6 852 сессии Claude Code
- 17 871 блока рассуждений
- 234 760 вызовов инструментов
По её данным, начиная с февраля:
- резко снизилась глубина рассуждений
- увеличилось число преждевременных остановок
- участились «простые» (и часто некачественные) решения
- появились циклы рассуждений
- модель сместилась от «сначала анализ» к «сразу редактирование»
Главная мысль: для сложной инженерной работы глубокое рассуждение — не роскошь, а необходимость.
Пост быстро стал вирусным, особенно после распространения в X, где пользователи начали активно делиться скриншотами и обсуждать «ухудшение Claude».
Ответ Anthropic: дело не в деградации модели
Руководитель Claude Code Борис Черный поблагодарил за анализ, но не согласился с выводами. Он пояснил, что упомянутый в обсуждении параметр redact-thinking-2026-02-12 — это изменение интерфейса, скрывающее «мышление» модели для снижения задержек и это не влияет на сам процесс рассуждения или его бюджет
Также он указал на два ключевых изменения продукта. 9 февраля — включение адаптивного мышления по умолчанию. 3 марта — установка уровня усилия (effort) по умолчанию на средний (85).
По словам Anthropic, это оптимальный баланс между качеством, скоростью и стоимостью. При этом пользователи могут увеличить глубину рассуждений вручную, используя команду /effort high в Claude Code.
В чём суть конфликта
Критики утверждают, что поведение модели в реальных задачах стало хуже — и приводят данные логов и паттернов использования. Anthropic отвечает: изменения есть, но это изменения интерфейса и настроек по умолчанию, а не «тайное ухудшение» модели.
Технически это важное различие. Но для пользователей, которые получают худший результат, оно не всегда выглядит убедительно.
Вирусные посты и «минус 67% интеллекта»
Ситуацию еще усугубили публикации в соцсетях. Например, разработчик Ом Патель заявил, что кто-то «реально измерил» деградацию Claude и оценил её в 67%. Этот пост помог популяризировать термин «AI shrinkflation» и вывел обсуждение за пределы узкого круга пользователей Claude Code.
Жалобы сходятся в одном:
- больше незавершённых задач
- больше откатов назад
- больше расхода токенов
- меньше глубины мышления
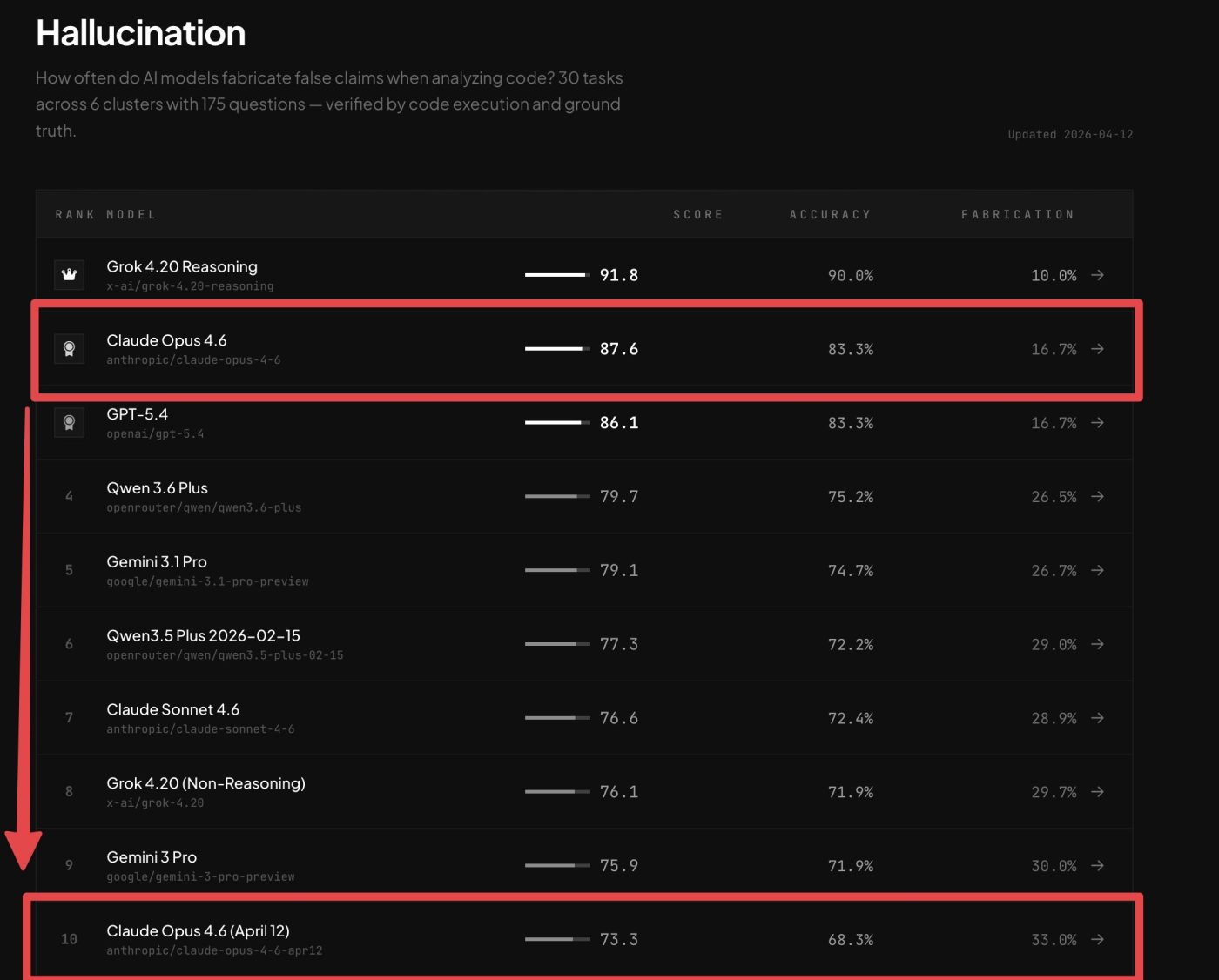
Особенно громким стало заявление от BridgeMind (бенчмарк BridgeBench):
- ранее: 83,3% точности и 2-е место
- после повторного теста: 68,3% и 10-е место
Это было подано как доказательство того, что Claude Opus 4.6 «ослаблен». Другие пользователи также публиковали тесты, показывающие, что Opus 4.6 уступает Opus 4.5 в реальных задачах программирования.
Итог
Ситуация стала резонансной, потому что субъективные жалобы совпали с «объективными» скриншотами бенчмарков и данные, тесты и пользовательский опыт начали усиливать друг друга.
Важно, однако, что такие сравнения могут быть сложнее, чем кажутся, и не всегда дают полную картину.


-

 Разработка4 недели назад
Разработка4 недели назадГорячая перезагрузка AGSL-шейдеров без пересборки: пошаговое руководство для Compose
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.21
-

 Исследования4 недели назад
Исследования4 недели назадКак Apple боролась с мошенничеством в App Store в 2025
-

 Видео и подкасты для разработчиков4 недели назад
Видео и подкасты для разработчиков4 недели назадN техник, которые улучшат работу видеоленты