Новости
Бенчмарк OpenAI протестировал LLM на реальных задачах фриланса
Выпуск SWE-Lancer свидетельствует как о быстром прогрессе, так и об остающихся проблемах, связанных с применением ИИ в разработке ПО.
Последний бенчмарк от OpenAI, SWE-Lancer, ставит простой, но провокационный вопрос: могут ли модели ИИ конкурировать с человеческими инженерами-фрилансерами? На основе более чем 1400 реальных заданий на Upwork — от исправления ошибок за 50 долларов до создания фич за 32 000 долларов — бенчмарк пытается измерить практические способности ИИ к кодингу. Вердикт? Несмотря на впечатляющие достижения, ИИ все еще не справляется с поставленными задачами, он может выполнить лишь малую часть заданий.
Большие языковые модели (LLM) изменили разработку программного обеспечения, но предприятиям придется дважды подумать о полной замене инженеров-программистов LLM, несмотря на заявления генерального директора OpenAI Сэма Альтмана о том, что модели могут заменить инженеров «низкого уровня».В новой статье исследователи OpenAI подробно рассказывают о том, как они разработали бенчмарк для LLM под названием SWE-Lancer, чтобы проверить, сколько модели могут заработать на реальных задачах по разработке программного обеспечения на фрилансе. Тест показал, что, хотя модели могут исправлять ошибки, они не могут понять, почему ошибки существуют, и продолжают совершать новые ошибки.
В отличие от предыдущих бенчмарков, которые фокусируются на изолированных проблемах программирования, SWE-Lancer отражает всю сложность реальной программной инженерии. Задачи охватывают весь жизненный цикл разработки, от доработки UI/UX и исправления ошибок до проектирования сложных архитектур. В набор данных также включены управленческие задачи, в которых ИИ должен оценить и выбрать наилучшее предложение по реализации, что отражает процесс принятия решений руководителями программных предприятий.
Чтобы сделать оценку максимально реалистичной, OpenAI оценивал независимые задачи, используя тройную проверку сквозных тестов, написанных профессиональными инженерами. Управленческие решения сравнивались с теми, которые принимали оригинальные менеджеры по найму.
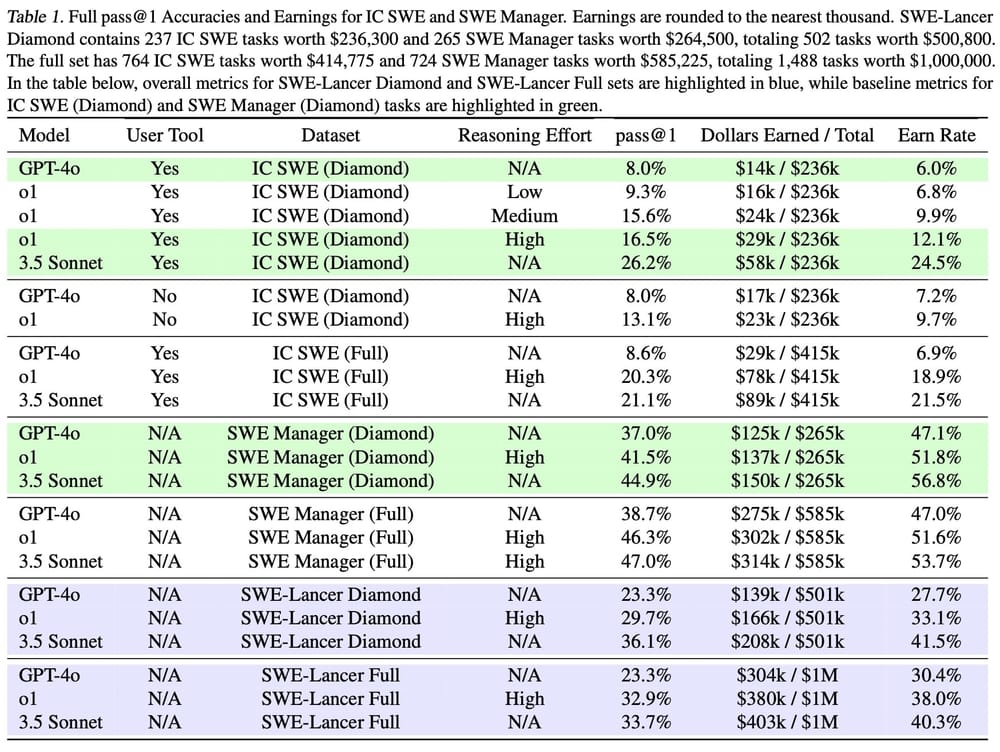
Результаты показали, что ИИ все еще испытывает трудности с разработкой реального программного обеспечения. Модель Claude 3.5 Sonnet от Anthropic, показавшая наилучшие результаты, заработала на всех заданиях чуть более 400,000 долларов из возможного 1 миллиона. Собственная модель OpenAI GPT-4o и другие модели показали еще худшие результаты, не справившись с большинством заданий. В заданиях, требующих написания и отладки кода, модели показали еще более низкий процент успеха, что подчеркивает ограниченность возможностей современного ИИ в выполнении всего объема работ по разработке программного обеспечения.
Одним из ключевых результатов SWE-Lancer является попытка оценить возможности ИИ в области разработки программного обеспечения в финансовых терминах. Связывая результаты работы с реальными выплатами, OpenAI предоставляет более ощутимую меру ценности ИИ для кодеров. Такой подход может помочь компаниям и политикам более эффективно оценить экономическое влияние ИИ на рынок труда в сфере программного обеспечения.
Чтобы стимулировать дальнейшие исследования, OpenAI выложила в открытый доступ часть набора данных под названием SWE-Lancer Diamond, который включает в себя публичный оценочный сплит с заданиями стоимостью 500,800 долларов. Исследователи могут использовать этот набор данных для сравнения новых моделей и изучения стратегий, направленных на улучшение способности ИИ решать сложные проблемы программной инженерии.
Выпуск SWE-Lancer свидетельствует как о быстром прогрессе, так и об остающихся проблемах, связанных с применением ИИ в разработке ПО. Хотя модели демонстрируют значительные улучшения в способности к кодированию — всего за несколько лет они перешли от задач из учебников к конкурентному программированию — SWE-Lancer показывает, что ИИ еще далек от того, чтобы заменить инженеров-людей. Бенчмарк предоставляет ценную проверку реальности ограничений ИИ и дорожную карту для будущих достижений в области автоматизированной разработки программного обеспечения.


-

 Интервью4 недели назад
Интервью4 недели назадМаркетологи в мобайле: Анастасия Луканова (руководитель направления по развитию рекламного бизнеса RuStore)
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.26
-

 Магазины приложений4 недели назад
Магазины приложений4 недели назадApple просто убила App Store
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.27