Новости
Chat with RTX от NVIDIA позволяет запускать генеративные модели на ПК
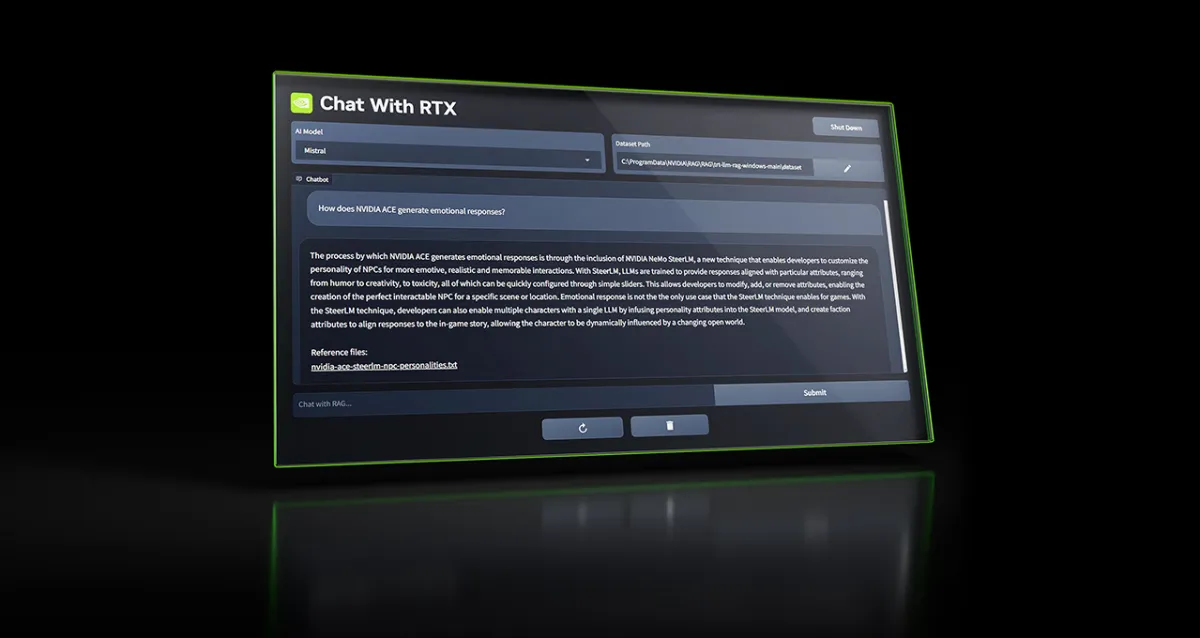
По умолчанию Chat with RTX использует модель ИИ с открытым исходным кодом от стартапа Mistral, но поддерживает и другие текстовые модели.
Компания Nvidia, стремящаяся стимулировать покупку своих новейших графических процессоров, выпустила инструмент, позволяющий владельцам карт GeForce RTX 30 и 40 серий запускать чатбота на базе искусственного интеллекта в автономном режиме на ПК с Windows.
Инструмент под названием Chat with RTX позволяет пользователям настраивать ИИ-модель по аналогии с ChatGPT от OpenAI, подключая ее к документам, файлам и заметкам, которые она затем может использовать.
«Вместо того чтобы самостоятельно искать в заметках или сохраненном контенте, пользователи могут просто вводить запросы», — пишет Nvidia в своем блоге. «Например, можно спросить: Какой ресторан рекомендовал мой партнер в Лас-Вегасе?, и Chat with RTX просканирует локальные файлы, на которые укажет пользователь, и предоставит ответ с контекстом».
По умолчанию Chat with RTX использует модель ИИ с открытым исходным кодом от стартапа Mistral, но поддерживает и другие текстовые модели, включая Llama 2 от Meta*. Nvidia предупреждает, что загрузка всех необходимых файлов займет изрядный объем памяти — от 50 до 100 ГБ, в зависимости от выбранной модели (моделей).
В настоящее время Chat with RTX работает с текстовыми, PDF, .doc, .docx и .xml форматами. Направив приложение на папку с любыми поддерживаемыми файлами, вы загрузите их в набор данных для тонкой донастройки модели. Кроме того, Chat with RTX может принимать URL-адрес плейлистов YouTube и загружать транскрипции видео, что позволяет любой выбранной модели “понимать” их содержимое.
При этом следует помнить о некоторых ограничениях, о которых Nvidia рассказывает в руководстве. Chat with RTX не запоминает контекст, а значит, приложение не будет учитывать предыдущие вопросы при ответе на последующие. Например, если вы спросите «Какая птица распространена в Северной Америке?», а затем в ответе на вопрос спросите «Какого цвета она бывает?», Chat with RTX не поймет, что вы говорите о птицах.
Nvidia также признает, что на релевантность ответов приложения может влиять целый ряд факторов, некоторые из которых легче контролировать, чем другие — в том числе формулировка вопроса, производительность выбранной модели и размер набора данных для тонкой настройки. Запрос фактов, освещенных в паре документов, скорее всего, даст лучшие результаты, чем запрос краткого содержания документа или набора документов. А качество ответов в целом улучшится при увеличении объема базы данных — как и при использовании в Chat with RTX большего количества контента по конкретной теме, говорят в Nvidia.
Таким образом, Chat with RTX — это скорее игрушка, чем что-то, что можно использовать в реальном проекте. Тем не менее, это приложение говорит о растущем тренде — облегчении локального запуска ИИ-моделей.
В недавнем докладе Всемирный экономический форум предсказал «резкий» рост числа доступных устройств, способных запускать генеративные ИИ-модели в автономном режиме, включая ПК, смартфоны, устройства Интернета вещей и сетевое оборудование. Причины, по мнению ВЭФ, кроются в очевидных преимуществах: Оффлайновые модели не только более приватны по своей сути — данные, которые они обрабатывают, никогда не покидают устройство, на котором они работают, — но и имеют меньшую задержку и более экономичны, чем модели, размещаемые в облаке.
Конечно, демократизация инструментов для запуска и обучения моделей открывает двери для злоумышленников — беглый поиск в Google дает множество объявлений о моделях, настроенных на токсичный контент. Однако сторонники таких приложений, как Chat with RTX, утверждают, что польза от них перевешивает вред. Нам остается только ждать и смотреть.


-

 Интервью4 недели назад
Интервью4 недели назадМаркетологи в мобайле: Анастасия Луканова (руководитель направления по развитию рекламного бизнеса RuStore)
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.26
-

 Магазины приложений4 недели назад
Магазины приложений4 недели назадApple просто убила App Store
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.27