AppsFlyer
AppsFlyer: Пирамида потребностей данных
Как мы можем сделать так, чтобы данные достигли «пика своего существования» и работали соответствующим образом? Другими словами, решением каких проблем стоит заняться при разработке архитектуры данных, если вы хотите, чтобы она была полной и позволяла получать понимание и ценности из данных, которые вы сгенерировали и собрали?
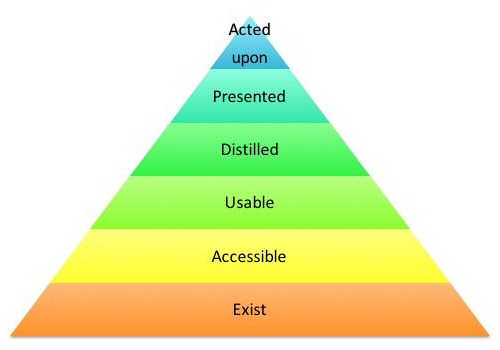
Несколько недель назад Нир Рубинштейн и я представляли архитектуру данных AppsFlyer на встрече Big Data & Data Science Israel. Одна из концепций, которую я там показывал – «Пирамида потребностей данных»:
- Данные должны существовать
- Данные должны быть доступны
- Данные должны быть пригодны к употреблению
- Данные должны быть дистиллируемы
- Данные должны быть представимы
Как мы можем сделать так, чтобы данные достигли «пика своего существования» и работали соответствующим образом? Другими словами, решением каких проблем стоит заняться при разработке архитектуры данных, если вы хотите, чтобы она была полной и позволяла получать понимание и ценности из данных, которые вы сгенерировали и собрали?
Если все сделано правильно, ваши пользователи смогут просто пользоваться данными, которые вы предоставляете. Список может показаться немного упрощенным, но это не законченный рецепт того, что надо делать, а скорее набор памяток в этой области и вопросов, на которые надо ответить для создания правильной архитектуры.
Данные должны существовать
Конечно, в первую очередь данные должны существовать и они, вероятно, существуют. Однако, вы должны спросить себя – правильные ли данные существуют? Отвечает ли политика хранения вашим бизнес потребностям? Отвечает ли их доступность вашим нуждам? Есть ли у вас все нужные ссылки (внешние ключи) к другим данным для последующего анализа?
Чтобы быть более конкретными, давайте рассмотрим следующим пример. AppsFlyer отслеживает несколько типов событий (запуск, события внутри приложений и т.д.), привязанных к приложению. Приложения привязаны к аккаунтам (у аккаунта, как правило, несколько приложений, как минимум iOS и Android версия одного). Если бы мы хранили аккаунты как последний снапшот и приложение изменило бы владельца, то исторические данные до смены были бы потеряны. Но если мы рассматриваем аккаунты как медленно меняющиеся события, то мы можем обрабатывать перенос правильно. Обратите внимание, что мы все еще можем предоставить новому владельцу исторические данные, но сейчас это не единственная возможность, реализованная в системе, и решения могут приниматься основываясь на бизнес-потребностях.
Данные должны быть доступны
Если данные пишутся на диск, то они (как минимум) доступны программно, но тут много уровней доступности и нам надо думать о потребностях наших конечных пользователях и том уровне, который необходим им. В AppsFlyer все существующие данные (упоминаемые выше) обрабатываются пропусканием сообщений из запросов через Kafka. Но данные сохраняются в последовательностях файлов в соответствии со временем события. Большинство наших сценариев использования включает временной компонент, но они в основном обрабатываются приложением или аккаунтом. Любой задаче, которая нужна конкретному аккаунту, понадобится пробиться через мириады записей (3.7+ миллиарда в день на момент написания этой статьи) для поиска тех, что необходимы. Таким образом, главный шаг к доступности данных это сортировка по приложению так, чтобы запрос получал доступ только к маленькому набору данных и работал бы намного быстрее.
Затем нам нужно учесть «температуру» данных, то есть, какое время отклика нам нужно для определенных данных. Например, отчеты о возвратах нам нужны онлайн (так называемый «sub-second» отклик), последние счетчики нужны примерно в реальном времени, исследование данных в поиске новых шаблонов может занимать часы и т.д. Чтобы поддерживать все эти пользовательские сценарии, нам нужно создать несколько проекций наших данных, скорее всего используя несколько разных технологий. AppsFlyer хранит raw-данные в последовательностях файлов, обработанные данные в паркетных файлах (доступных через Apache Spark), агрегированные и последние данные в реляционных базах данных, а те, что нужны в реальном времени – в памяти.
У трех разных механизмов хранения, которые я упомянул выше (Parquet, СУБД и дата грид в памяти) и которые использует AppsFlyer, у всех у них есть SQL доступ – и это не случайно. В то время как мы (индустрия) проходили через короткий период NoSQL, SQL или почти-SQL вернулись в строй, даже для полу-структурированных и поли-структурированных данных. Предоставление SQL интерфейса к вашим данным это еще одна важная задача в доступности данных, так как он позволяет расширить вашу пользовательскую базу за пределы R&D отделов. Опять же, это важно не только для ваших реляционных данных…
Данные должны быть годными к употреблению
Какая разница между доступностью (accessible) и годностью к употреблению (usable) данных? Для последнего необходима очистка данных. Это нелегкая задача, если вы собираете данные из разрозненных систем, но она необходима, даже если вашим источником служит одна система. Очистка данных это все то, чем занимается традиционный ETL, и все техники оттуда до сих пор применимы.
Другой аспект превращения данных в удобные, заключается в их обогащении или подключении к дополнительным источникам. Обогащение может проходить внутренними данными, например, подключением CRM в данным аккаунта. Оно также может идти и от внешних источников, например, получением категории для приложения из магазина или размера экрана из базы данных устройств.
Последнее, но не менее важное – нужно рассмотреть вопросы легальности и приватности данных. До того, как дать доступ, возможно, вам надо скрыть важную информацию или удалить приватные данные (иногда и в первую очередь вам даже нельзя сохранять такие данные). В AppsFlyer мы очень серьезно подходим к этим вопросами и прилагаем большие усилия для соответствия всем нормам при работе с партнерами и клиентами, чтобы убедиться в том, что конфиденциальные данные обрабатываются правильно. На самом деле, мы даже проводим независимый аудит железа для того, чтобы соответствовать самым высоким стандартам.
Подводя итого, чтобы сделать данные годными к употреблению, надо убедиться, что они корректные, соединить их с другими данными и убедиться, что они соответствуют правовым и конфиденциальным политикам.
Данные должны быть дистиллированы
Дистилляция идей и есть цель всех предыдущих шагов. От данных, самих по себе, мало пользы, если они не помогают принимать лучшие решения. Есть множество типов инсайтов, которые вы можете получить. Начиная от более традиционных сценариев бизнес-разведки и slice and dice аналитики, проходя через агрегацию в реальном времени и аналитику трендов, и заканчивая машинным обучением или «продвинутой» аналитикой. Примером того, что можно почерпнуть из данных, служит наш Gaming Advertising Performance Index, который мы опубликовали недавно.
Данные должны быть представимы
Этот пункт как раз прекрасно иллюстрирует отчет Gaming Advertising Performance. Получение инсайтов это важный шаг, но если вы не сможете показать их последовательным и связанным образом, то настоящие пользователи смогут сделать из них лишь ограниченные выводы. Обратите внимание, что даже если вы используете инсайты для принятия решений (например, рекомендовать продукт пользователю), то вы все равно должны представлять насколько хорошо они будут воплощены.
Есть много вопросов, которые надо решить с точки зрения взаимодействия пользователей с данными и их представления. Простой пример первого — какую форму графиков использовать. Пример второго – во время представления прогнозируемых или неправильных данных пользователям должно быть понятно, что они смотрят на приближение.
Убедиться в том, что все описанные выше вопросы обрабатываются правильно, непростая задача, но предоставление системы, которая действительно помогает вашим пользователям принимать правильные решения, стоит того. Пирамида потребностей данных не рецепт того, как сделать все правильно, это набор точек, которые помогут вам дойти до цели. Они помогают мне целостно думать о потребностях данных AppsFlyer и я надеюсь, что следование написанному в этом посте поможет и вам.
Материал предоставлен компанией AppsFlyer.
Автор:
 |
Арнон Ротем-Гал-Оз, Chief Data Officer в Appsflyer. У Арнона за плечами более 20 лет разработки, управления проектами и построения архитектуры больших распределенных систем на разных платформах и технологиях. |


-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.25
-

 Интервью4 недели назад
Интервью4 недели назадМаркетологи в мобайле: Анастасия Луканова (руководитель направления по развитию рекламного бизнеса RuStore)
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.26
-

 Магазины приложений3 недели назад
Магазины приложений3 недели назадApple просто убила App Store