Разработка
Как Discord использует Elixir для работы пяти миллионов пользователей одновременно
Как Discord удается справляться с огромными нагрузками? Ему в этом помогает Elixir — функциональный, распределённый язык программирования общего назначения, который работает на виртуальной машине Erlang. В этой статье компания рассказывает о том, с какими проблемами она столкнулась при масштабировании и как их решала.

С самого начала Discord использует Elixir. Erlang VM был идеальным кандидатом для создания системы с большим количеством одновременно работающих пользователей. Мы создали оригинальный прототип Discord на основе Elixir, он стал основой нашей существующей инфраструктуры. Elixir обещал объединить силу Erlang VM с более современным языком программирования и набором инструментов.
Два года спустя у нас почти пять миллионов пользователей находятся в системе одновременно, в ней происходят миллионы событий каждую секунду. Пока мы не пожалели о выборе инфраструктуры, так как произвели много исследований и экспериментов, чтобы прийти к ней. Elixir — это новая экосистема, а о работе экосистемы Erlang не хватает информации (хотя Erlang in Anger отлична). Дальше я расскажу о полученных нами уроках и созданных библиотеках.
Разветвление сообщений
Хотя в Discord много функций, многие из них сводятся к модели pub/sub. Пользователи подключаются к WebSocket и запускают сессию (GenServer), которая затем общается с удаленными узлами Erlang, работают guild-процессы (внутренние для сервера Discord). Когда что-либо публикуется в гильдии, это разветвляется в каждую подключенную сессию.

Когда пользователь выходит в онлайн, он или она подключается к гильдии, а гильдия публикует событие в другие подключенные сессии. У гильдии есть и другая логика, но вот простой пример:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def handle_call({:publish, message}, _from, %{sessions: sessions}=state) do | |
| Enum.each(sessions, &send(&1.pid, message)) | |
| {:reply, :ok, state} | |
| end |
Это было хорошим подходом, когда мы создавали Discord для групп до 25 человек. Нам достаточно повезло, что появились “хорошие проблемы” роста, когда люди начали использовать Discord для больших групп. В итоге на многих серверах Discord одновременно начали общаться до 30 тысяч пользователей, как в /r/Overwatch. Во время часов пик мы начали видеть, что процессы не справляются с потоком сообщений. В конкретный момент нам пришлось вручную отключить функции, которые генерировали сообщения, чтобы помочь справляться с загрузкой.
Мы начали измерять занимающие больше всего времени пути в процессах гильдии и быстро натолкнулись на причину проблемы. Отправка сообщения через процессы Erlang была не такой дешевой, и снижение стоимости — единица работы Erlang, которая используется для планирования процессов — было тоже высоким. Мы обнаружили, что время простого запроса send/2 менялось от 30 микросекунд до 70 микросекунд из-за повторного планирования Erlang процесса вызова. Это означало, что во время часов пик публикация события из гильдии могла занимать от 900 миллисекунд до 2,1 секунды. Единственным способом было разделить эти процессы и сделать работу параллельной. Это было большим делом, но мы знали, что так будет лучше.
Мы знали, что должны распределить работу по отправке сообщений. Так как создавать процессы в Erlang незатратно, нашим первым предположением было просто создавать новый процесс для каждой публикации. Однако каждая публикация должна была происходить в разное время, а клиенты Discord полагаются на линейность событий. Это решение также нельзя было масштабировать, так как на сервис гильдий ложилось все большее количество работы.
После этого поста в блоге родился Manifold. Manifold распределяет работу по отправке сообщений к удаленным узлам на PID (идентификатор процесса Erlang), которые гарантируют, что отправка процессов вызывает send/2 в количестве, равном числу удаленных узлов. Manifold делает это посредством группировки PID по их удаленному узлу и отправки на Manifold.Partitioner каждого из этих узлов. Разделитель затем хеширует PID, используя erlang.phash2/2, группирует их по количеству ядер, а потом отправляет дочерним воркеры. Так можно убедиться, что разделитель не перегружается и предоставляет линейность, гарантированную send/2. Это решение стало заменой send/2:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Manifold.send([self(), self()], :hello) |
Отличным побочным эффектом Manifold стала возможность не только распределять нагрузку на CPU при помощи разделения сообщений, но и сокращение трафика сети между узлами. Manifold доступен на нашем GitHub.
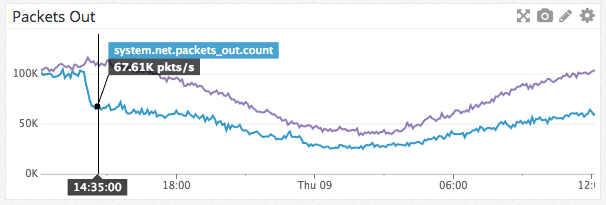
Быстрый доступ к данным
Discord — это распределенная система, которая основана на постоянном хешировании. Этот метод позволяет нам создать кольцевую структуру данных, которую можно использовать, чтобы найти конкретный узел объекта. Мы хотим, чтобы этот процесс был быстрым, поэтому выбрали библиотеку от Криса Муса. Она хорошо работала, но когда Discord начал расширяться, мы начали замечать проблемы, когда многие пользователи переподключались. Ответственный за контроль кольца процесс Erlang был перегружен настолько, что он не мог справляться с запросами, и перегружалась вся система. Решение сначала казалось очевидным: запустить несколько процессов с кольцевыми данными, чтобы лучше использовать все ядра машины для ответа на запросы. Мы заметили, что этот путь будет слишком долгим. Можем ли мы сделать это лучше?
Разберем этот процесс:
- Пользователь может быть в любом количестве гильдий, но среднее количество составляет пять.
- Ответственный за процессы Erlang VM может поддерживать до 500 тысяч сессий одновременно.
- Когда сессия подключается, она должна искать удаленный узел для каждой нужной гильдии.
- Стоимость соединения с другим процессом Erlang через request/reply составляет около 12 микросекунд.
Если сервер с сессиями перестанет работать и перезапустится, только поиск данных займет 30 секунд. Это без учета повторного планирования Erlang процесса, вовлеченного в кольцо. Можем ли мы полностью устранить эту проблему?
Если вы хотите ускорить доступ к данным в Elixir, первым делом нужно применить ETS. ETS — это быстрый и изменяемый словарь, разработанный на C, и компромисс заключается в том, что данные копируются в него и из него. Мы не могли просто переместить наше кольцо в ETS, так как для его контроля мы использовали C-порт, поэтому мы перенесли код на чистый Elixir. Как только это было сделано, у нас был процесс, функцией которого было постоянно переносить кольцо в ETS, чтобы другие процессы могли читать данные напрямую из ETS. Это значительно улучшило производительность, но чтение из ETS занимало около 7 микросекунд, и поиск значений в кольце по-прежнему занимал 17,5 секунд. Кольцевая структура данных довольно большая, и копирование её в ETS и из него занимало почти все время. Мы были разочарованы: на другом языке мы бы могли просто создать безопасное для чтения распределенное значение. Должен же быть способ сделать это в Erlang!
В итоге мы нашли mochiglobal, модуль, который использует функцию VM: если Erlang видит функцию, которая возвращает одни и те же данные, он помещает эти данные в кучу только для чтения, в которую процессы могут получить доступ без копирования данных. mochiglobal создает модуль Erlang с одной функцией и компилирует его. Так как данные не копируются, поиск занимает 0,3 микросекунды, а все время сократилось до 750 миллисекунд. Однако создание модуля для структуры вроде кольца может занять до секунды. Но мы редко меняем структуру, так что мы готовы были принять этот недостаток.
Мы решили перенести mochiglobal на Elixir и добавить функциональности. Наша версия называется FastGlobal и доступна на https://github.com/discordapp/fastglobal.
Ограниченная пропускная способность
После решения проблемы с производительностью процесса поиска узла, мы заметили, что процессы, ответственные за поиск guild_pid, стали тормозить. Раньше эти процессы защищались медленным поиском в узлах. Новой проблемой стало то, что почти 5 миллионов процессов сессий пытались давить на десять этих процессов (по одному на каждый узел). Ускорение этой обработки не решило бы проблему: проблема заключалась в том, что вызов процесса сессии в этом реестре гильдий прерывался и оставлял запрос в очереди в реестр гильдии. Он затем пытался повторить запрос, но в итоге только копил запросы и переходил в состояние, из которого его нельзя было восстановить. Сессии блокировали эти запросы до тех пор, пока не получали сообщения от других сервисов, что вело к увеличению очереди сообщений, и во всем Erlang VM заканчивалась память.
Нам нужно было сделать процессы сессии умнее: если провал неизбежен, то эти запросы вообще не стоит делать. Мы не хотели использовать прерыватель, потому что не хотели, чтобы большое количество перерывов приводило к состоянию, в котором не совершались бы никакие попытки. Мы знали, как это сделать в других языках, но как решить проблему в Elixir?
В других языках мы бы использовали атомарный счетчик, чтобы отследить выделяющиеся запросы и внедрять семафор. Erlang VM построен вокруг координации коммуникации между процессами, но мы знали, что не хотим перегружать ответственный за эту координацию процесс. После изучения вопроса мы нашли :ets.update_counter/4, который выполняет атомарные операции в ключе ETS. Так как нужно было большое количество одновременных операций, мы могли бы запустить ETS в узле write_concurrency, но значение все равно бы было получено, так как :ets.update_counter/4 возвращает результат. Это дало нам основу для создания библиотеки Semaphore. Её просто использовать и она дает хорошие результаты:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| semaphore_name = :my_sempahore | |
| semaphore_max = 10 | |
| case Semaphore.call(semaphore_name, semaphore_max, fn -> :ok end) do | |
| :ok -> | |
| IO.puts "success" | |
| {:error, :max} -> | |
| IO.puts "too many callers" | |
| end |
Библиотека оказалась эффективной в защите нашей инфраструктуры. У нас недавно возникла похожая ситуация с накоплением сбоев, но система осталась невредимой. Наши службы присутствия обрушились, но службы сеанса даже не сдвинулись с места, и службы присутствия смогли перестроиться в течение нескольких минут после перезапуска.
Вы можете найти нашу библиотеку Semaphore на GitHub.







