Разработка
Внедрение ИИ в ваше приложение: используем Foundation модели Apple
После многих лет борьбы с ключами API, ограничениями токенов и сетевыми ошибками это кажется обманом. Вся интеграция ИИ занимает около 100 строк кода. Никаких внешних зависимостей. Никаких файлов конфигурации. Она просто работает.
Первое, что я сделал, посмотрев кейноут WWDC25 и State of the Union — поигрался с новым API Liquid Glass. Мне потребовалось несколько дней, чтобы запустить Ice Cubes, а версия 2.0 будет в полной мере использовать новейшую систему дизайна Liquid Glass в iOS, iPadOS и MacOS.

Напоминаю, что это приложение с открытым исходным кодом, и вы можете следить за поддержкой iOS 26 в репозитории на GitHub.
Но я знал, что надо заняться чем-то серьезным — мне нужно было погрузиться в новый фреймворк Apple Foundation Models и посмотреть, смогу ли я заменить свою реализацию OpenAI новым API.
Ссылки и документация
Основная документация по этому новому фреймворку находится здесь. Вот отрывок из введения:
«Фреймворк Foundation Models предоставляет доступ к большой языковой модели Apple на устройстве, которая поддерживает Apple Intelligence, помогая вам выполнять интеллектуальные задачи, специфичные для вашего варианта использования. Текстовая модель на устройстве определяет шаблоны, которые позволяют генерировать новый текст, подходящий для вашего запроса, и может принимать решения о вызове написанного вами кода для выполнения специализированных задач.
[…]
Чтобы расширить возможности модели на устройстве, используйте Tool для создания пользовательских инструментов, которые модель может вызывать для помощи в обработке вашего запроса. Например, модель может вызывать инструмент, который ищет информацию в локальной или онлайн-базе данных, или вызывать службу в вашем приложении».
Эта сессия действительно разожгла интерес, чтобы применить это в Ice Cubes. Это видео обязательно к просмотру, и оно наверняка заставит вас задуматься о новых возможностях фреймворка для ваших приложений:
Также есть подробная сессия, охватывающая многие другие темы, которые я не буду освещать.
Хочу сделать вступление: то, что я сделал с Ice Cubes, — это лишь малая часть и демонстрация того, что вы можете сделать с помощью этого фреймворка. Я пока даже не использую функцию Tool. Например, создав свой инструмент и указав модели вызывать его, вы можете обернуть любой другой фрейм или системный вызов, чтобы его можно было вызвать из промпта.
Я планирую более подробно изучить возможности этого фреймворка с помощью другого приложения, которое я скоро создам. Однако Ice Cubes — отличный пример, поскольку это уже существующий продукт со встроенными функциями ИИ.
В моей предыдущей статье вы можете посмотреть, что я сделал в Ice Cubes с помощью OpenAI.
Помощник
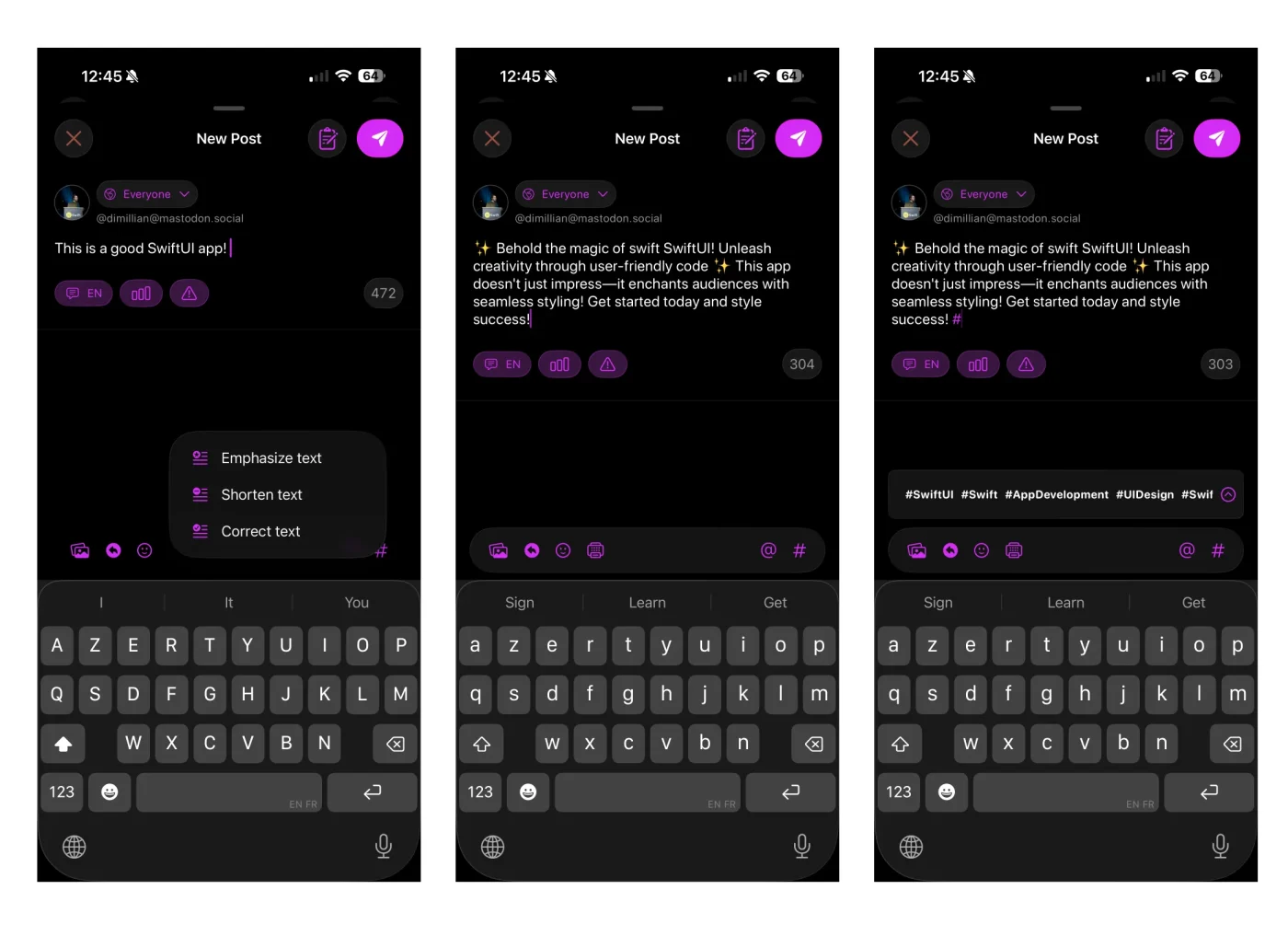
Ice Cubes может исправить, сократить или переписать пост, который вы в данный момент составляете, используя ИИ.
Новое, что я добавил, и что было так просто с моделью на устройстве, это предложение хэштега, связанного с сообщением, которое вы в данный момент пишете.
Одна из функций, которая пока останется в API OpenAI Vision — это предоставление альтернативного текстового описания изображения. Это удобная и мощная функция, которой ежедневно пользуются сотни пользователей. Я не могу перенести ее сейчас, потому что модели Apple на устройстве пока не поддерживают изображения в качестве входных данных.
Настройка Foundation
Сначала вам нужно импортировать FoundationModels и создать сессию:
@available(iOS 26.0, *)
struct Assistant {
private static let model = SystemLanguageModel.default
public static var isAvailable: Bool {
return model.isAvailable
}
private let session = LanguageModelSession(model: .init(useCase: .general)) {
"""
Your job is to assist the user in writing social media posts.
The users is writing for the Mastodon platforms, where posts are usually not longer than 500 characters.
"""
}
}
Обратите внимание, как я проверяю доступность! Это важно. Модель не всегда есть — это зависит от того, включен ли и готов ли Apple Intelligence на устройстве. И поддерживает ли устройство Apple Intelligence вообще.
Также важно отметить: при обновлении Ice Cubes до iOS 26 я прекратил поддержку функций ИИ для всех устройств, не работающих на iOS, macOS, iPadOS 26 и не поддерживающих Apple Intelligence.
Не все смогут это сделать. Решением могло бы быть сохранение реализации OpenAI, но я пытаюсь упростить кодовую базу и хочу, чтобы приложение также было простым для внедрения новых фич. Так что это жертва, на которую я готов пойти.
Магия @Generable и @Guide
Вот где все становится интересным. Хотите структурированный вывод вместо парсинга строк? Просто используйте макрос @Generable:
@Generable
struct Tags {
@Guide(description: "The value of the hashtags, must be camelCased and prefixed with a # symbol.", .count(5))
let values: [String]
}
Аннотации @Guide — это как мини-подсказки для каждого свойства. Я сообщаю модели именно то, что мне нужно: хэштеги в camelCased с символами # и не более 5 штук.
Генерация хэштегов
Это до смешного просто, когда все готово.
func generateTags(from message: String) async -> Tags {
do {
let response = try await session.respond(
to: "Generate a list of hashtags for this social media post: \(message).",
generating: Tags.self
)
return response.content
} catch {
return .init(values: [])
}
}
Никакого парсинга JSON. Никаких регулярных выражений. Просто запросите структуру Tags и получите ее обратно. Фреймворк обрабатывает всю магию преобразования.
Потоковые ответы
Для исправлений и изменений текста я использую потоковую передачу, чтобы показывать результаты по мере их генерации:
func correct(message: String) async -> LanguageModelSession.ResponseStream<String>? {
session.streamResponse(
to: "Fix the spelling and grammar mistakes in the following text: \(message).",
options: .init(temperature: 0.3)
)
}
Обратите внимание на настройки температуры? Более низкая температура (0,3) для исправлений сохраняет точность. Более высокая температура (2,0) для функции «переписывания» делает ее более креативной:
func emphasize(message: String) async -> LanguageModelSession.ResponseStream<String>? {
session.streamResponse(
to: "Make this text catchy, more fun: \(message).",
options: .init(temperature: 2.0)
)
}
Интеграция UI
Пользовательский интерфейс чистый — просто кнопка меню, которая показывает различные параметры ИИ:
if #available(iOS 26, *), Assistant.isAvailable {
Menu {
ForEach(AIPrompt.allCases, id: \.self) { prompt in
Button {
Task {
isLoadingAIRequest = true
await focusedText.runAssistant(prompt: prompt)
isLoadingAIRequest = false
}
} label: {
prompt.label
}
}
} label: {
Image(systemName: "faxmachine")
}
}
Обработка потока
При обработке потокового ответа я сначала создаю резервную копию исходного текста (пользователи оценят возможность отмены):
@available(iOS 26.0, *)
func runAssistant(prompt: AIPrompt) async {
let assistant = Assistant()
var newStream: LanguageModelSession.ResponseStream<String>?
switch prompt {
case .correct:
newStream = await assistant.correct(message: statusText.string)
case .emphasize:
newStream = await assistant.emphasize(message: statusText.string)
case .fit:
newStream = await assistant.shorten(message: statusText.string)
}
if let newStream {
backupStatusText = statusText
do {
for try await content in newStream {
replaceTextWith(text: content)
}
} catch {
if let backupStatusText {
replaceTextWith(text: backupStatusText.string)
}
}
}
}
Каждый фрагмент обновляет текстовое поле в реальном времени. Если что-то пойдет не так, мы восстановим резервную копию, что просто.
Демо
Реальная производительность
Вот что меня поразило: это быстро — действительно быстро. Модель на устройстве реагирует на эти простые задачи почти мгновенно. Нет сетевой задержки, ограничений скорости API и затрат на токен.
Исправления происходят менее чем за секунду. Генерация хэштега в основном занимает менее 2 секунд. Даже функция «переписывания» с ее более высокой температурой работает быстро.
Опыт разработчика
После многих лет борьбы с ключами API, ограничениями токенов и сетевыми ошибками это кажется обманом. Вся интеграция ИИ занимает около 100 строк кода. Никаких внешних зависимостей. Никаких файлов конфигурации. Она просто работает.
Один только макрос @Generable экономит десятки строк кода парсинга. Помните парсинг ответов JSON и надежду, что ИИ отформатирует их правильно? Да, я тоже там был — я уже заблокировал эти воспоминания.
Вы можете увидеть фактическое подтверждение здесь, где я заменяю большую часть своей реализации OpenAI на это.
Советы профессионалам: как сделать ИИ еще быстрее
Предварительный разогрев
Вы можете предварительно разогреть сеанс, чтобы предотвратить задержку при первом использовании модели в вашем приложении. Система разумно управляет моделью на устройстве — ее может не быть в памяти, если устройство обслуживает другие критически важные функции или она не используется.
Вот трюк: предварительно разогрейте сеанс, когда пользователи проявляют намерение:
// When the compose view appears or when user starts typing assistant.session.prewarm()
Вызов этого метода не гарантирует, что система немедленно загрузит ваши ресурсы, особенно если ваше приложение работает в фоновом режиме или система находится под нагрузкой.
Но также помните о предупреждении выше из документации.
В Ice Cubes идеальный момент — когда кто-то открывает экран для написания поста. К тому времени, как он напечатает свой пост и будет готов использовать функции ИИ, модель уже будет загружена.
Сессия WWDC показала, что это может сэкономить 1–2 секунды при первом использовании. Это разница между «вау, это мгновенно» и «ух, почему это так долго загружается?».
На данный момент в Ice Cubes мне еще нужно внести некоторые улучшения кода, например, предварительный разогрев и сохранение помощника и сессии активными, а не их повторное создание каждый раз, когда пользователь использует одну из функций ИИ.
Оптимизация схемы: меньше токенов, больше скорости
Вот кое-что неочевидное: при использовании типов @Generable фреймворк автоматически включает вашу схему в каждый промпт. Для моей структуры Tags это означает отправку определения структуры с каждым запросом.
Вы можете отключить это для хорошего повышения производительности:
let response = try await session.respond(
to: "Generate hashtags for: \(message)",
generating: Tags.self,
options: .init(includeSchemaInPrompt: false)
)
Когда это следует делать?
- Последующие запросы в том же сеансе (модель уже знает вашу схему)
- Когда ваши инструкции включают примеры ожидаемого вывода
В моем случае, поскольку я делаю одноразовые запросы, я сохраняю схему включенной. Но если вы создаете интерфейс, похожий на чат, с несколькими дополнениями, отключите ее после первого запроса.
Настройка температуры
// Corrections: Low temperature (0.3) = predictable, accurate
func correct(message: String) async -> ResponseStream<String>? {
session.streamResponse(to: prompt, options: .init(temperature: 0.3))
}
// Creative tasks: Higher temperature (2.0) = more variation
func emphasize(message: String) async -> ResponseStream<String>? {
session.streamResponse(to: prompt, options: .init(temperature: 2.0))
}
Значение по умолчанию — 1,0, но настройка имеет огромное значение. Переписывания с высокой температурой «исправят» то, что не сломано. Творческие задачи с низкой температурой скучны. Температуру можно установить в диапазоне от 0 до 2.
Потоковая передача или ожидание
Для всего, что длиннее предложения, используйте потоковую передачу:
// Don't do this for long responses
let response = try await session.respond(to: prompt, generating: String.self)
// Do this instead
for try await chunk in session.streamResponse(to: prompt) {
updateUI(with: chunk)
}
Пользователи видят прогресс немедленно. Психологическая разница колоссальна — даже если общее время одинаковое.
Проблемы симулятора
Вот на чем документация не акцентирует внимание: производительность на симуляторе ≠ производительность на устройстве.
Тестирование на симуляторе M4 Mac даст вам нереально быстрые результаты. Всегда профилируйте на реальном оборудовании.
Инструмент Foundation Models в Xcode вам здесь поможет.
Также стоит упомянуть, что это не будет работать в симуляторе iOS 26, если вы также не используете macOS 26
Правильная обработка доступности
Не просто проверьте isAvailable один раз. Модель может стать недоступной (давление системы, отключение пользователем и т. д.):
static var isAvailable: Bool {
// This is dynamic - check it before each use
return SystemLanguageModel.default.isAvailable
}
Я показываю/скрываю меню AI на основе этой проверки. Нет смысла показывать кнопки, которые не сработают.
Промпт-инжиниринг для скорости
Более короткие и прямые подсказки быстрее:
// Slower "Please analyze the following social media post and generate appropriate hashtags that would be relevant for the Mastodon platform: \(message)" // Faster "Generate hashtags for: \(message)"
Модель уже настроена на полезность. Вам не нужно быть вежливым с умножением матриц.
И я уверен, что найду еще много профессиональных советов, продолжая изучать этот фреймворк.
Но пока что, счастливого кодирования!


-

 Аналитика магазинов4 недели назад
Аналитика магазинов4 недели назадМобильный рынок Ближнего Востока: выручка растёт быстрее загрузок: исследование Bidease и Sensor Tower
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.24
-

 Разработка4 недели назад
Разработка4 недели назадЧто нового в SwiftUI после WWDC26
-

 Разработка4 недели назад
Разработка4 недели назадЧто нового в UIKit после WWDC26