Разработка
Как машинное обучение в Spotify находит вашу новую любимую музыку
Среди всех музыкальных сервисов Spotify стал первой компанией, объединившей несколько моделей анализа песен. Разработчица София Чиокка рассказала, какие именно механизмы позволяют Spotify находить песни, которые понравятся именно вам.
Среди всех музыкальных сервисов Spotify стал первой компанией, объединившей несколько моделей анализа песен. Разработчица София Чиокка рассказала, какие именно механизмы позволяют Spotify находить песни, которые понравятся именно вам.
В этот понедельник, как и в каждый понедельник, более 100 миллионов пользователей Spotify открыли ожидающий их новый плейлист. Это индивидуальный микс из тридцати песен, которые они никогда не слышали, но которые им, вероятно, понравятся. Это называется Discover Weekly, и это похоже на магию.
Я огромная фанатка Spotify, а особенно Discover Weekly. Почему? Я чувствую, что меня видят. Spotify знает мои музыкальные вкусы лучше, чем любой человек в моей жизни, и я восхищаюсь тем, что каждую неделю я слышу в подборке отличные треки, которые сама бы никогда не нашла.
Те, кто незнаком с сервисом, познакомьтесь с моим виртуальным лучшим другом:
Оказалось, что я не одна одержима Discover Weekly. Пользователи сходят от него с ума, что привело к тому, что Spotify смещает свой фокус, инвестируя больше ресурсов в плейлисты, основанные на алгоритмах.
С тех пор, как Discover Weekly появился в 2015 году, мне не терпелось узнать, как он работает. После трех недель поиска информации, мне удалось заглянуть за занавес.
Итак, как Spotify так хорошо подбирает 30 песен для каждого человека каждую неделю? Давайте сделаем шаг назад и посмотрим на то, как делают рекомендации другие музыкальные сервисы и как Spotify справляется с этой задачей лучше.
Краткая история отбора музыки

В 2000-х рекомендации музыки начались с Songza, в котором использовали ручной отбор, чтобы создавать плейлисты для пользователей. “Ручное курирование” означало, что команда “музыкальных экспертов” или других кураторов вручную составляла плейлисты, которые хорошо звучали, а пользователи просто слушали их. (Позже эту же стратегию применили Beats Music). Ручной отбор хорошо работал, он был простым, но он не принимал во внимание индивидуальный музыкальный вкус каждого слушателя.
Как и Songza, Pandora была одним из первопроходцев в области отбора музыки. Они применили более сложный подход, вручную проставив теги с атрибутами песен. Это означало, что люди слушали музыку и выбирали несколько тегов для каждой песни. Затем алгоритм Pandora фильтровал песни по определенным тегам, чтобы создавать плейлисты с похожей музыкой.
Примерно в то же время в MIT Media Lab на свет появилось агентство The Echo Nest, которое предложило более радикальный подход к персонализированной музыке. The Echo Nest использовали алгоритмы, чтобы анализировать текстовое и музыкальное содержание песен для идентификации музыки и создания персональных рекомендаций и плейлистов.
И, наконец, ещё один подход использует Last.fm. Это процесс под названием коллаборативная фильтрация, о котором я расскажу чуть позже.
Как же в Spotify создали волшебный алгоритм, который отслеживает вкусы каждого пользователя гораздо точнее, чем другие сервисы?
Три типа моделей рекомендаций Spotify
Spotify использует не одну революционную модель. Вместо этого они совмещают несколько лучших стратегий, чтобы создать собственный мощный рекомендательный движок.
Чтобы создать Discover Weekly, Spotify применяет три главных типа моделей:
- Модели совместной фильтрации (их применяет Last.fm), которые анализирует ваше поведение и поведение других пользователей.
- Модели обработки естественного языка (NLP), которые работают на основе анализа текста.
- Аудио-модели, которые анализируют необработанное аудио.

Давайте посмотрим на каждую из этих моделей.
Совместная фильтрация

Для начала немного информации: когда люди слышат о совместной фильтрации, они вспоминают Netflix, так как именно эта компания одной из первых применила совместную фильтрацию для создания рекомендательной модели, которая использовала оценки пользователей, чтобы понять, какие фильмы рекомендовать другим “аналогичным” пользователям.
После того, как Netflix это удалось, эту модель стали использовать все чаще, и теперь она является стартовой точкой для всех желающих создать рекомендательный движок.
Однако в Spotify нет пользовательских оценок для музыки. Вместо этого данные Spotify основаны на неявной обратной связи, то есть, на песнях, которые мы послушали, а также на дополнительных данных, например, сохранили ли пользователи трек в своей плейлист или посетили ли они страницу исполнителя после прослушивания.
Но что такое совместная фильтрация, и как она работает? Вот краткое описание в виде небольшого диалога:

Что здесь происходит? У каждого из них есть свои предпочтения: человеку слева нравятся песни P, Q, R и S, а человеку справа — Q, R, S и T. Совместная фильтрация использует эти данные, чтобы предложить человеку справа послушать P, а человеку слева — трек T. Все просто, да?
Но как Spotify использует эту концепцию, чтобы создать рекомендации для миллионов пользователей, основываясь на миллионах предпочтений других людей? Матричные вычисления при помощи библиотек Python.

Эта матрица на самом деле огромна. Каждый ряд представляет одного из 140 миллионов пользователей Spotify, а каждая колонка представляет одну из 30 миллионов песен в базе Spotify. Затем библиотека Python запускает эту длинную и сложную формулу факторизации матрицы:

Когда вычисления закончены, мы получаем два типа векторов, обозначенных здесь как X и Y. X — это вектор пользователя, представляющий вкус одного пользователя, а Y — вектор песни, представляющий профиль отдельно взятой песни.

Теперь у нас есть 140 миллионов векторов пользователей и 30 миллионов векторов песен. Содержимое этих векторов — это числа, бессмысленные по отдельности, но крайне важные для сравнения.
Чтобы обнаружить пользователей со схожим с моим вкусом, совместная фильтрация сравнивает мой вектор с векторами других пользователей. То же относится и к вектору Y — вы можете сравнить вектор данной песни с векторами других песен, чтобы найти наиболее похожие на конкретный трек.
Совместная фильтрация работает достаточно хорошо, но Spotify добавляет и другие механизмы. Перейдем к NLP.
Обработка естественного языка
Второй тип рекомендательных моделей — модели обработки естественного языка (NLP). Источник данных этих моделей — слова. Это метаданные песен, новостные статьи, блоги и другие тексты в интернете.

Обработка естественного языка, то есть, способность компьютера понимать человеческую речь как она есть, это обширное поле, которое часто предшествует анализу смысла.
Мы не будем рассматривать механизмы NLP, поэтому вот поверхностное объяснение того, что происходит. Spotify постоянно ищет тексты о музыке и вычисляет, что люди говорят о конкретных исполнителях и песнях: какие прилагательные они используют и какие другие песни и исполнители часто упоминаются рядом.
Хотя я не знаю, как именно Spotify обрабатывает собранные данные, я могу сказать, как с ними работали The Echo Nest. Они распределяли данные на “культурные векторы” или “основные термины”. У каждого исполнителя и у каждой песни были тысячи меняющихся ежедневно основных терминов. К каждому термину было привязано свое значение, которое показывало, насколько важно это описание (то есть, вероятность, с которой кто-то опишет эту музыку этим термином).

Затем, как и в совместной фильтрации, NLP-модель использует эти термины и значения, чтобы создать векторное представление, которое используется для сравнения песен.
Модели необработанного аудио

Вы можете подумать: “У нас уже есть так много данных”. Зачем нам анализировать само аудио?”
Во-первых, третья модель улучшает точность этого рекомендательного сервиса. Но у этой модели есть и более важная цель: в отличие от двух предыдущих типов, она принимает во внимание новые песни.
Например, ваш друг написал песню и выложил её на Spotify. Может быть, её прослушали 50 раз, поэтому совместная фильтрация не сработает должным образом. Если её не упомянули нигде в интернете, то NLP-модели её не увидят. К счастью, аудио-модели не выделяют популярные песни и новые песни, поэтому с их помощью, песня вашего друга может попасть в Discover Weekly вместе с более известными песнями.
Как мы можем анализировать данные необработанного аудио, которые кажутся такими абстрактными? При помощи сверточных нейронных сетей!
Сверточные нейронные сети — это технология, которая используется и в распознавании лиц. Spotify модифицировали её для обработки аудиоданных вместо пикселей. Вот пример архитектуры нейронной сети:
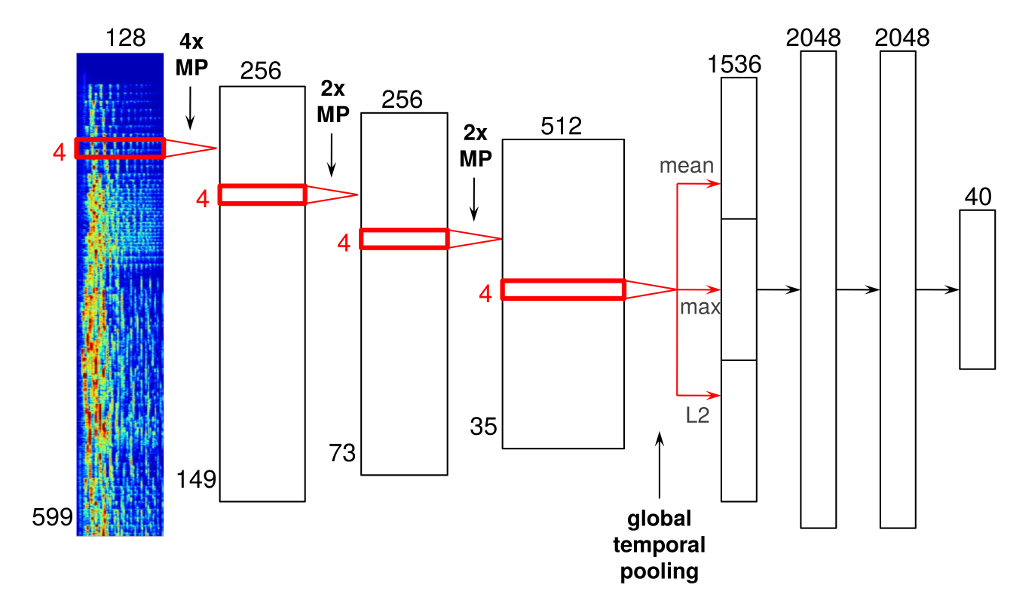
Эта нейронная сеть имеет четыре сверточных слоя (толстые полосы слева) и три плотных слоя (более узкие полосы справа). Входные данные представляют собой представления звуковых кадров со временем и частотой, которые затем конкатенируются для формирования спектрограммы.
Звуковые кадры проходят через сверточные слои, и результатом этого становится слой “глобального временного объединения”, который объединяет всю ось времени, эффективно вычисляя статистику изученных функций на протяжении песни. После обработки нейросеть выдает характеристики песни: время, тональность, лад, темп и громкость. Ниже вы можете видеть эти данные для 30-секундного отрывка песни Daft Punk “Around the World”.

В конце концов, эти ключевые характеристики песни позволяют Spotify понимать фундаментальные сходства песен и находить пользователей, которым эти песни должны понравиться.
В этом и заключаются основы трех основных типов рекомендательных моделей, на которых основан механизм Spotify и создание плейлиста Discover Weekly.

Конечно, все эти модели связаны в большую экосистему Spotify, которая включает огромное количество данных для рекомендательных моделей и использует множество кластеров Hadoop для обработки гигантских матриц бесконечного количества музыкальных статей и колоссального количества аудиофайлов.


-

 Интервью4 недели назад
Интервью4 недели назадМаркетологи в мобайле: Анастасия Луканова (руководитель направления по развитию рекламного бизнеса RuStore)
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.26
-

 Магазины приложений4 недели назад
Магазины приложений4 недели назадApple просто убила App Store
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.27