Автоматическое тестирование приложений
Почему мы отказались от модульного тестирования классов и перешли на поведенческий подход
Я не говорю, что вы должны выбрать только один тип теста для своей системы, а просто то, что тип тестов, которые фокусируются на отдельных классах по отдельности, имеет несколько проблем, которые заставили нас полностью отказаться от них.
Недавно я написал пост, объясняющий, как мы удалили 80% нашего кода, избегая преждевременных абстракций, и как это значительно повысило эффективность разработки и уменьшило количество ошибок.
Один момент, который я в значительной степени не осветил в этой публикации, — это наше решение полностью прекратить писать модульные тесты для отдельных классов. Я не говорю, что вы должны выбрать только один тип теста для своей системы, а просто то, что тип тестов, которые фокусируются на отдельных классах по отдельности, имеет несколько проблем, которые заставили нас полностью отказаться от них. В этой статье я расскажу о наших аргументах в пользу этого выбора, а также о нашем альтернативном подходе, основанном на следующих основных проблемах с тестированием на уровне классов.
- Тесты классов делают изменения болезненными
- Тесты классов не проверяют фактическое поведение
- Тесты классов сложно понять
Давайте рассмотрим каждую из задач более подробно.
1. Тесты классов делают изменения болезненными
Модульное тестирование на уровне класса блокирует каждый класс в нашей кодовой базе, чтобы он работал определенным образом и использовал другие классы определенным образом. Несмотря на то, что модульные тесты уровня класса не должны проверять реализацию класса, сам класс, включая его методы и интерфейс, действует как деталь реализации с точки зрения системы в целом.
Это становится проблемой при внесении изменений в наш код, поскольку каждая небольшая модификация нарушает тесты. Поскольку типичные изменения в кодовой базе затрагивают несколько классов, нам чаще всего придется обновлять тесты для каждого отдельного класса, которого мы коснулись. Более того, нам может потребоваться обновить другие тесты, которые имитируют любой из измененных классов. Это становится утомительным и создает дополнительный барьер для изменения даже малейшей детали.

Обычные изменения приводят к сбою нескольких тестов
Даже когда мы изменяем только внутренние детали реализации, наши тесты будут ломаться и требовать обновления. Допустим, мы хотим реорганизовать один класс в два, чтобы мы могли повторно использовать часть логики в другом месте. Это немедленно нарушит тесты, требуя от нас удаления и обновления тестовых примеров для исходного класса, а также создания нового набора тестовых примеров для добавленного класса. А мы даже не изменили никакого внешнего поведения системы.
Вместо этого мы бы предпочли, чтобы тесты не проходили только при изменении внешнего поведения. Это позволило бы нам делать любой внутренний рефакторинг нашей кодовой базы без единого изменения наших тестов. Кроме того, мы бы предпочли, чтобы изменения нескольких классов в одном потоке — например, конечной точки микросервиса — требовали обновления только одного набора тестов, а не каждого теста для каждого затронутого класса.
2. Тесты классов не проверяют фактическое поведение
Тестирование на уровне класса фокусируется на отдельных классах. В результате мы тестируем детали реализации, а не поведение нашего кода в целом. Основным недостатком является то, что всякий раз, когда тест терпит неудачу, он ничего не сообщает нам о том, изменилось ли внешнее поведение нашего кода или нет, поскольку тесты могли просто потерпеть неудачу из-за изменения деталей реализации.
Это проблема даже тогда, когда все тесты остаются зелеными после изменения, что обычно указывает разработчикам, что все в порядке и безопасно для развертывания. Однако это часто не относится к этому типу тестов, поскольку мы полагаемся на имитацию других классов. Каждый раз, когда класс мокируется, делается предположение о том, как этот класс работает, которое быстро устаревает, когда сам класс изменяется, и мы забываем обновить макеты.
Например, предположим, что класс A обрабатывается, когда класс B возвращает результат X и проверяется имитацией B, чтобы действовать правильным образом. Если позже мы изменим класс B, чтобы начать также возвращать результат Y в некоторых сценариях, тогда, даже если A не обрабатывает этот новый случай, все его тесты по-прежнему будут зелеными, поскольку каждый мок B по-прежнему будет настроен на то, чтобы всегда возвращать X Если разработчики не будут помнить, что класс A зависим от B, то у нас будет сломанный код с полностью зелеными тестами.

Классовые тесты основываются на предположениях, которые быстро устаревают
Это означает, что даже когда тесты классов продолжают оставаться зелеными после изменения, мы не можем быть уверены, что код в целом действительно ведет себя правильно. Вместо этого мы бы предпочли, чтобы тесты, проходящие или не проходящие, были привязаны только к внешнему поведению нашей кодовой базы. Если тесты терпят неудачу, поведение изменилось, а если они проходят, то код ведет себя так же.
3. Тесты классов сложно понять
Мы только что рассмотрели, что изолированное тестирование классов мало что говорит о внешнем поведении нашего кода. В результате, чтобы действительно знать, работает ли поток кода после внесения изменений, нам нужно понимать каждый класс, участвующий в потоке, и покрывают ли их соответствующие тесты все необходимые случаи и все возможные результаты от классов, которые они мокируют.
Затем мы должны мысленно собрать все это вместе, чтобы сделать вывод, приведут ли вместе отдельные классы к правильному внешнему поведению потока. Это одновременно сложно и подвержено ошибкам, особенно когда изменение вносится кем-то, кто не знает наизусть каждый уголок кодовой базы.
Это еще больше усложняется тем фактом, что тестирование классов из-за того, что оно сосредоточено на деталях реализации, приводит к тому, что многие тесты часто ломаются и по разным причинам. Это означает, что разработчикам постоянно необходимо обновлять тесты, каждый раз с полным пониманием классов, участвующих в потоке, их тестов и того, как они могут по-разному влиять друг на друга после изменения.
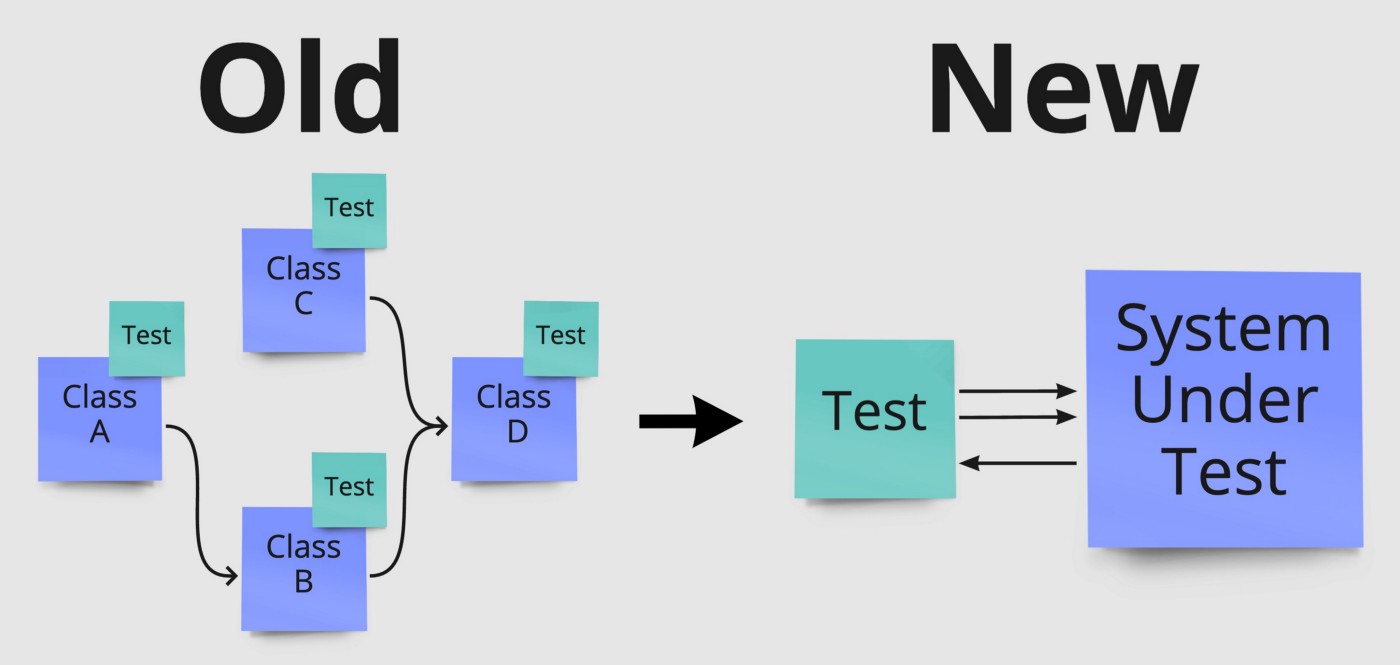
Давайте посмотрим на приведенный ниже пример, показывающий, как четыре класса используют друг друга.
Если класс D изменится, нам нужно будет не только понять и обновить тесты для D, но и понять его влияние на все классы, зависящие от D, и их соответствующие тесты.
В этом примере это будут классы B и C. Кроме того, поскольку B может вести себя по-разному из-за изменения D, нам также необходимо понять A и тесты этого класса.

Понять поведение из тестов класса сложно
Хотя понимание теста одного класса может быть несложным, оно запутывается, когда нам нужно сделать вывод о каком-либо внешнем поведении из этих тестов.
Вместо этого мы бы предпочли, чтобы одного тестового примера было достаточно, чтобы понять некоторую часть фактического внешнего поведения нашей кодовой базы.
Альтернатива модульному тестированию классов
Мы сделали выбор в пользу полного отказа от модульного тестирования на уровне классов, и поэтому нам, естественно, потребовался альтернативный подход к автоматическому тестированию. В первую очередь мы применяем эти концепции для тестирования отдельных микросервисов, но они также могут применяться ко многим другим типам систем, таким как нативные и веб-приложения или даже библиотеки.
Концепция
То, что мы в итоге получили, основано на базовой концепции обращения с нашей работающей системой как с черным ящиком, сосредоточенным только на внешнем поведении. Это означает, что в рамках наших тестов мы запускаем систему и выполняем все тесты, пока она работает. Мы стремимся обращаться с ней как с черным ящиком, насколько это возможно, поскольку это автоматически делает тесты независимыми от деталей реализации и фокусируется на поведении. По сути, вместо модульного тестирования классов мы рассматриваем всю нашу систему, например микросервис, как тестируемый модуль или систему.
Это наш наиболее детализированный тип тестирования, который по-прежнему сосредоточен только на поведении отдельной системы или кодовой базы. Могут потребоваться дополнительные типы тестов, чтобы гарантировать правильное поведение на всех этапах работы в нескольких системах. Однако я не буду рассказывать об этом в этом посте.
Мокинг внешних зависимостей
Обращаясь с нашей системой как с черным ящиком, мы больше не хотим имитировать, заглушать, дублировать или подделывать какие-либо внутренние части кодовой базы, поскольку тесты не должны касаться их.
Однако мы хотим имитировать внешние зависимости, поскольку это позволяет нам тестировать нашу систему изолированно. Определение того, что является внешним, а что нет, будет варьироваться от проекта к проекту в зависимости от того, что имеет смысл.
Например, при тестировании наших микросервисов базы данных рассматриваются как внутренние и, следовательно, не мокируются. Время рассматривается как внешний компонент и имитируется, как и HTTP-связь между системой и другими внешними системами. В случаях, когда наш микросервис использует очередь сообщений, может быть использован как тот, так и другой подход.
Сообщения, которые публикуются и используются самим микросервисом, не будут мокироваться, однако при публикации или получении каких-либо сообщений в или из других систем они будут имитироваться и рассматриваться как внешние. Это показано на иллюстрации ниже.

Внутреннее против Внешнего
Организация тестовых данных
Рассматривая работающую систему как черный ящик, мы хотим упорядочить тестовые данные и предоставить ввод точно так же, как это происходило бы при работе в реальной среде.
Для микросервиса это может быть вызов конечных точек, которые он предоставляет, или публикация сообщений во внешней очереди, которые использует служба.
Для внешнего интерфейса это может быть фактическое нажатие кнопок и навигация по пользовательскому интерфейсу аналогично тому, как это делал бы пользователь.
Используя этот подход, мы гарантируем, что все тесты основаны на реальных состояниях приложения, точно так же, как они появляются в производственной среде. Кроме того, поскольку все вызывается через разрешенный ввод в систему, мы никогда не будем тратить время на тестирование случаев, которые не могут произойти в реальности, что является дополнительным преимуществом.

Организация тестовых данных путем вызова внешних конечных точек
Чтобы упростить написание и сопровождение тестов, стоит создать многократно используемые методы для систематизации часто используемых тестовых данных. Примером может быть работа с пользователями в базе данных. Вместо того, чтобы делать HTTP-запрос для создания пользователей в каждом отдельном тесте, переместите его в метод многократного использования, который может вызывать каждый тестовый пример.
Утверждение результата
Располагая тестовыми данными, мы готовы выполнить действие в нашей системе и подтвердить результат. Поскольку мы по-прежнему относимся к нашей системе как к черному ящику, мы стремимся утверждать только внешние результаты, вызванные нашим действием.
Примерами внешних результатов может быть HTTP-ответ в случае, если нашим действием был HTTP-запрос. Кроме того, внешними результатами также могут быть исходящие HTTP-вызовы, сделанные системой, и сообщения, опубликованные во внешней очереди сообщений.

Утверждение внешних результатов действия. Галочки обозначают пункты утверждения.
При настройке моков для подтверждения правильного внешнего поведения нашей системы рассмотрите возможность использования моков в строгом режиме. Они должны быть строгими в том смысле, что они приводят к сбою тестов всякий раз, когда вызываются с любым вводом, для обработки которого они не были специально настроены. Это гарантирует не только правильность действий нашей системы, но и отсутствие неожиданного поведения. Мы не хотим совершать HTTP вызовы и отправлять сообщения в другие системы, когда мы этого не должны.
Время выполнения
При замене классических модульных тестов на уровне классов поведенческими тестами системы мы должны убедиться, что наши тесты по-прежнему выполняются быстро. Это одно из преимуществ модульных тестов на уровне класса, поскольку они не зависят ни от чего, кроме самого класса, что обычно делает их чрезвычайно быстрыми. Когда тесты внезапно начинают работать с HTTP-вызовами и запросами к базе данных, время их выполнения может увеличиться.
Решение этой проблемы зависит от используемой вами технологии. В нашем конкретном случае использования ASP.NET TestServer было достаточно для быстрого выполнения HTTP-запросов, а замена нашей базы данных вариантом в памяти при локальном запуске тестов помогла повысить скорость запросов.
Однако, прежде чем пул-реквест может быть принят, все тесты запускаются с реальной базой данных, поскольку вариант в памяти никогда не будет вести себя точно так же. Важно найти хороший баланс между временем выполнения и максимально реалистичными внутренними зависимостями.
Вывод
Вот и все, мы полностью избавились от модульных тестов классов. Наш новый подход полностью сосредоточен на поведении, и в результате, когда тесты проходят, мы знаем, что те же самые случаи будут работать и для реального пользователя системы.
Нам больше не нужно обновлять тесты каждый раз, когда меняются детали реализации, что позволяет нам беспрепятственно выполнять любые внутренние рефакторинги.
Наконец, больше нет необходимости собирать вместе несколько разных классов и тестов в сознании разработчиков, чтобы сделать вывод о поведении — теперь достаточно чтения одного изолированного тестового примера, чтобы понять и проверить, как ведет себя система.


-

 Аналитика магазинов3 недели назад
Аналитика магазинов3 недели назадМобильный рынок Ближнего Востока: выручка растёт быстрее загрузок: исследование Bidease и Sensor Tower
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.23
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.24
-

 Разработка4 недели назад
Разработка4 недели назадПриоритизация эффективности использования памяти: важные шаги для Android 17