Новости
Meta открыла мультисенсорную модель ИИ, объединяющую шесть типов данных
На данный момент эта модель является лишь исследовательским проектом, не имеющим немедленного потребительского или практического применения, но она указывает на будущее генеративных систем ИИ.
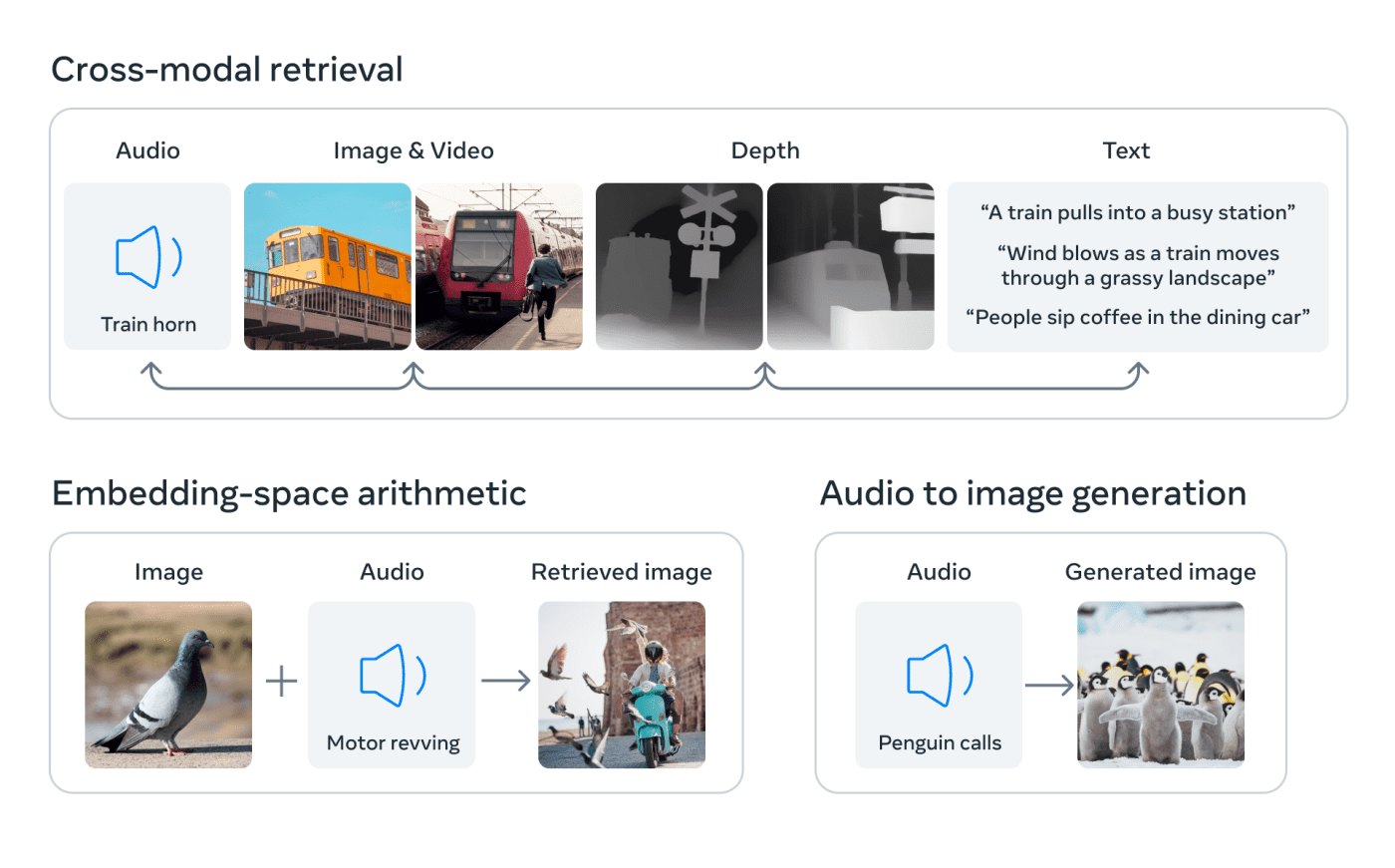
Компания Meta* анонсировала новую ИИ-модель с открытым исходным кодом, которая связывает вместе несколько потоков данных, включая текст, аудио, визуальные данные, температуру и данные о движении.
На данный момент эта модель является лишь исследовательским проектом, не имеющим немедленного потребительского или практического применения, но она указывает на будущее генеративных систем ИИ, способных создавать иммерсивный, мультисенсорный опыт, и показывает, что Meta продолжает делиться исследованиями в области ИИ в то время, когда конкуренты, такие как OpenAI и Google, становятся все более закрытыми.
Основная концепция исследования заключается в объединении нескольких типов данных в единый многомерный индекс (или embedding space, «пространство встраивания», если говорить на языке ИИ). Эта идея может показаться несколько абстрактной, но именно она лежит в основе недавнего бума генеративного ИИ.
Например, такие ИИ-генераторы изображений, как DALL-E, Stable Diffusion и Midjourney, опираются на системы, которые связывают текст и изображения на этапе обучения. Они ищут закономерности в визуальных данных, связывая эту информацию с описаниями изображений. Именно это позволяет этим системам генерировать изображения, которые соответствуют текстовым данным пользователя. То же самое можно сказать и о многих инструментах ИИ, которые генерируют видео или аудио таким же образом.
Meta утверждает, что ее модель ImageBind — первая, объединяющая шесть типов данных в единое пространство встраивания. В модель включены следующие шесть типов данных: визуальные (в виде изображений и видео); тепловые (инфракрасные изображения); текст; аудио; информация о глубине; и — самое интригующее из всего — показания движения, генерируемые инерциальным измерительным блоком, или IMU (IMU можно найти в телефонах и смарт-часах, где они используются для выполнения целого ряда задач, от переключения телефона из альбомной ориентации в портретную до определения различных видов физической активности).
Идея заключается в том, что будущие системы искусственного интеллекта смогут сопоставлять эти данные так же, как это делают нынешние системы искусственного интеллекта при вводе текста. Представьте себе, например, футуристическое устройство виртуальной реальности, которое генерирует не только аудио- и визуальные данные, но и данные о вашем окружении и движении на физической сцене. Вы можете попросить устройство имитировать длительное морское путешествие, и оно не только поместит вас на корабль с шумом волн на заднем плане, но и покачает палубу под вашими ногами и овеет прохладой океанского воздуха.
В своем блоге Meta отмечает, что в будущие модели могут быть добавлены и другие потоки сенсорного ввода, включая «прикосновения, речь, запах и сигналы МРТ мозга». Компания также утверждает, что исследование «делает машины на один шаг ближе к способности человека учиться одновременно, целостно и непосредственно из многих различных форм информации».
Конечно, все это очень спекулятивно, и, скорее всего, непосредственное применение подобных исследований будет гораздо более ограниченным. Например, в прошлом году компания Meta продемонстрировала модель ИИ, которая генерирует короткие и размытые видео из текстовых описаний. Работа, подобная ImageBind, показывает, как будущие версии системы могут включать в себя другие потоки данных, например, генерировать аудио в соответствии с видео.
Для отраслевых наблюдателей исследование интересно еще и тем, что Meta предоставляет открытый доступ к базовой модели — все более необычная практика в мире ИИ.
Противники открытого доступа, такие как OpenAI, говорят, что эта практика вредна для создателей, поскольку конкуренты могут копировать их работу, и что она может быть потенциально опасной, позволяя злоумышленникам воспользоваться преимуществами современных моделей ИИ. Сторонники отвечают, что open source позволяет сторонним разработчикам тщательно изучить системы на предмет недостатков и устранить некоторые из их них. Они отмечают, что это может даже принести коммерческую выгоду, поскольку позволяет компаниям использовать сторонних разработчиков в качестве неоплачиваемых работников для улучшения своей работы.
До сих пор Meta твердо стояла на позициях открытого исходного кода, хотя и не без некоторых вопросов (например, ее последняя языковая модель, LLaMA, стала всеобщим достоянием по случайности). Во многом отсутствие коммерческих достижений в области ИИ (у компании нет чат-бота, который мог бы соперничать с Bing, Bard или ChatGPT) позволило использовать этот подход. И в настоящее время, с ImageBind, компания продолжает следовать этой стратегии.


-

 Интервью4 недели назад
Интервью4 недели назадМаркетологи в мобайле: Анастасия Луканова (руководитель направления по развитию рекламного бизнеса RuStore)
-

 Новости4 недели назад
Новости4 недели назадВидео и подкасты о мобильной разработке 2026.26
-

 Магазины приложений4 недели назад
Магазины приложений4 недели назадApple просто убила App Store
-

 Новости3 недели назад
Новости3 недели назадВидео и подкасты о мобильной разработке 2026.27